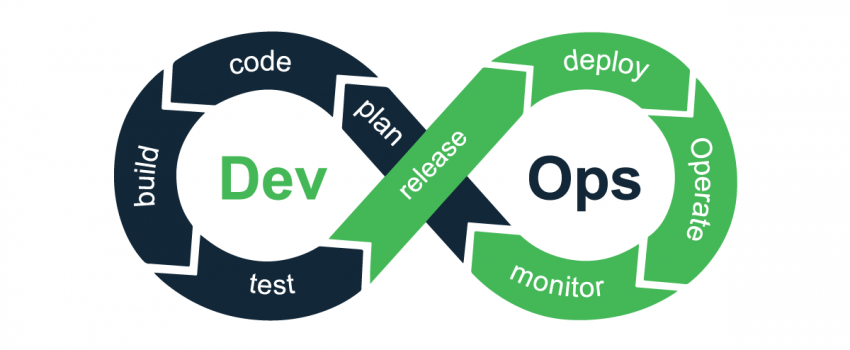
Cette boucle, on la connaît tous par cœur. On nous la présente dans toutes les formations et tous les articles sur le DevOps. On sait ce qu’est le CI (Continuous Integration) et le CD (Continuous Delivery). On a appris qu’il faut automatiser, tester, livrer vite et souvent pour améliorer nos applications.
Cette théorie, on la maîtrise. Dans notre veille ou nos projets, on passe énormément de temps à parler de Git, Docker, Kubernetes, Terraform, Ansible… Mais on a tendance à survoler, voire à complètement oublier, une partie essentielle de la boucle : la phase “Monitor”, qui est en réalité la porte d’entrée vers un concept bien plus vaste et fondamental : l’observabilité.
Alors, c’est quoi au juste, l’observabilité ?
Pour faire simple, l’observabilité est la capacité de poser des questions à notre système pour comprendre son état interne, sans avoir à le modifier. C’est notre capacité à “voir” ce qui se passe à l’intérieur.
Vous allez me dire : “Attends, mais c’est du monitoring, ça ! On le fait déjà.”
Et c’est là que la confusion s’installe souvent. Meme s’il sont liés, le monitoring et l’observabilité ne sont pas la même chose. Comprendre les différences, c’est comprendre l’évolution de la supervision de nos infrastructures.
Monitoring : Répondre aux questions que l’on connaît DÉJÀ
Le monitoring traditionnel, c’est comme le tableau de bord de votre voiture. Il est conçu pour répondre à des questions que l’on a anticipées, des problèmes connus.
- Mon CPU est-il utilisé à plus de 90% ? (Quelle est ma vitesse ?)
- Mon espace disque est-il presque plein ? (Me reste-t-il de l’essence ?)
- Mon serveur web répond-il au ping ? (Le moteur est-il allumé ?)
On surveille des métriques bien définies, et si un seuil est dépassé, un voyant rouge s’allume sur notre dashboard. C’est ce qu’on appelle les “connus connus” (known knowns). C’est indispensable, mais dans le monde des architectures modernes (microservices, cloud, conteneurs…), ce n’est pas du tout suffisant.
Mon serveur peut très bien répondre au ping, mais l’application qui tourne elle sur mon serveur, peut être en panne, ou une API critique peut renvoyer des erreurs 500 à la moitié de nos utilisateurs. Le voyant “moteur allumé” est vert, mais la voiture n’avance plus.
C’est exactement cela, la différence essentielle entre le monitoring et l’observabilité. Le monitoring vous dit QUE quelque chose ne va pas, mais il ne vous dit pas POURQUOI (dans les details)
Observabilité : Explorer les problèmes que l’on ne POUVAIT PAS prévoir
Reprenons notre analogie. Votre voiture se met à faire un bruit étrange et à vibrer, mais uniquement en troisième vitesse, en montée, et seulement quand il pleut (un scenario bizarre :) ). Le tableau de bord dans ce cas il ne sert a rien. Il n’a pas été conçu pour cette question.
Pour comprendre l’origine du problème, vous n’avez pas le choix : il faut ouvrir le capot. Écouter d’où vient le bruit, vérifier les niveaux, brancher un outil de diagnostic sur l’ordinateur de bord… Bref, vous devez enquêter en profondeur.

L’observabilité, c’est ça. C’est la capacité de votre système à vous laisser ouvrir le capot. Elle est conçue pour vous aider à explorer les “inconnus inconnus” (unknown unknowns), ces pannes étranges et ces bugs vicieux qui n’apparaissent que dans des conditions très spécifiques.
Pour résumer la différence en une phrase :
- Le monitoring vous dit QUE quelque chose ne va pas.
- L’observabilité vous donne les outils pour comprendre POURQUOI.
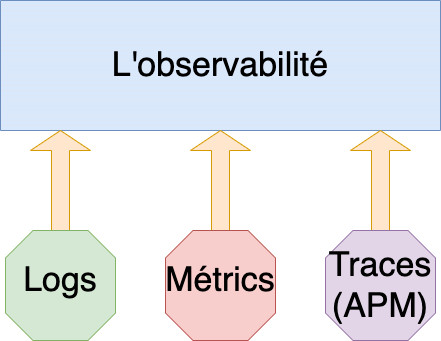
Les 3 Piliers de l’Observabilité
Pour qu’un système soit considéré comme “observable”, il doit nous fournir des données riches et variées. Ces données sont généralement classées en trois catégories, qu’on appelle les trois piliers de l’observabilité :
-
Les Métriques : Le “Quoi” Ce sont des mesures numériques collectées à intervalles réguliers (ex: utilisation CPU, RAM, nombre de requêtes par seconde). Elles sont parfaites pour les dashboards et les alertes. C’est le pilier du monitoring classique.
-
Les Logs : Le “Pourquoi” Ce sont des enregistrements textuels et horodatés d’événements spécifiques qui se sont produits (ex:
User 'makhal' logged in,Database connection failed,File not found). Ils donnent le contexte détaillé d’un événement. -
Les Traces : Le “Où” C’est le pilier le plus moderne, indispensable pour les microservices. Une trace suit le parcours complet d’une seule requête à travers tous les services qu’elle traverse. Si une requête est lente, la trace vous montrera exactement quel service est le goulot d’étranglement.
Le début du voyage, pas la destination
Aujourd’hui, ne pas penser à l’observabilité dès le début de ses projets, c’est comme construire une voiture sans compteur, sans voyants, sans bruit. Le monitoring, c’est un point de départ. Mais l’observabilité, c’est ce qui nous permet d’avoir un vrai regard intérieur sur ce que vivent nos systèmes.
Pour affronter les problèmes modernes, il nous faut des outils qui écoutent, tracent, enregistrent, et surtout… nous permettent de poser les bonnes questions.
Et pour vraiment comprendre comment ces outils fonctionnent, rien de mieux que de construire la première brique nous-mêmes.
Notre premier pas pratique : un agent de métriques en Go
Nous allons maintenant construire notre propre agent, ou exporter, en Go. Il sera simple, mais il nous montrera tout le mécanisme de l’intérieur.
Notre premier pas pratique : un agent de métriques en Go
Nous allons maintenant construire notre propre agent, ou exporter, en Go. Il sera simple, mais il nous montrera tout le mécanisme de l’intérieur.
Avant de coder, il faut comprendre ce que Prometheus attend. Quand il contacte un endpoint /metrics, il s’attend à recevoir du texte brut dans un format spécifique :
# HELP nom_metrique Description de la métrique.
# TYPE nom_metrique type_de_metrique
nom_metrique{label="valeur"} valeur_numerique
# HELP: Une explication pour les humains.# TYPE: Le type de métrique (counterqui augmente toujours,gaugequi peut monter/descendre).- La ligne de métrique : Nom, labels (étiquettes) et la valeur numérique.
Le Code de notre agent
Créez un fichier main.go :
package main
import (
"fmt"
"log"
"net/http"
"runtime"
)
func metricsHandler(w http.ResponseWriter, r *http.Request) {
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Fprintln(w, "# HELP go_memstats_alloc_bytes Nombre de bytes alloués.")
fmt.Fprintln(w, "# TYPE go_memstats_alloc_bytes gauge")
fmt.Fprintf(w, "go_memstats_alloc_bytes %d\n", m.Alloc)
fmt.Fprintln(w, "# HELP go_goroutines Nombre de goroutines actives.")
fmt.Fprintln(w, "# TYPE go_goroutines gauge")
fmt.Fprintf(w, "go_goroutines %d\n", runtime.NumGoroutine())
}
func main() {
http.HandleFunc("/metrics", metricsHandler)
log.Println("Démarrage de l'exporter sur http://localhost:9091/metrics")
log.Fatal(http.ListenAndServe(":9091", nil))
}
Lançons-le !
Dans un terminal :
go run main.go
Dans un autre terminal :
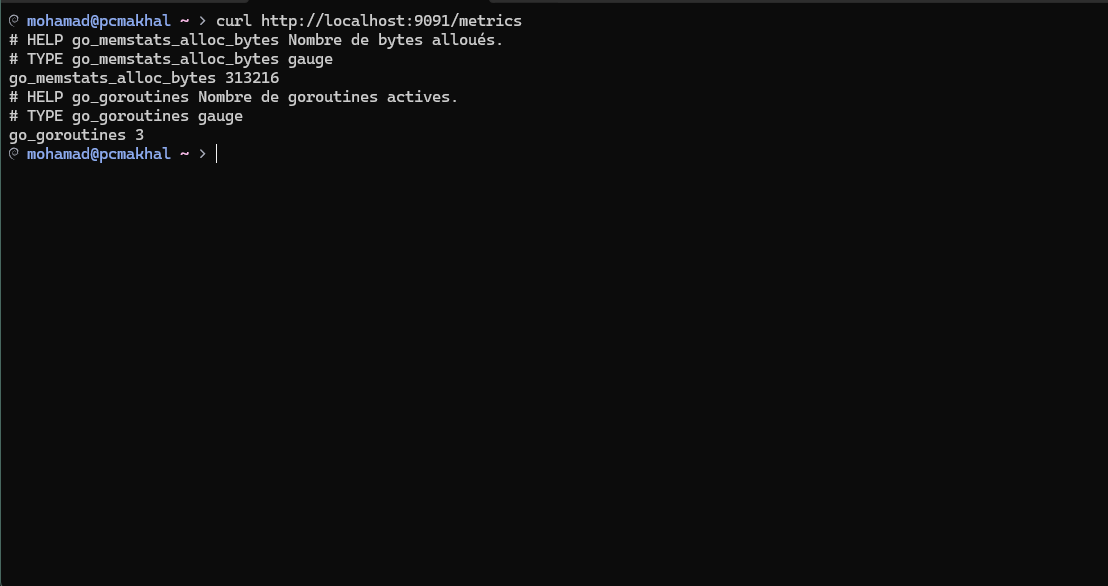
curl http://localhost:9091/metrics
Vous devriez voir les métriques s’afficher, formatées correctement comme suit :
Conclusion
Et voilà ! Nous avons non seulement compris la théorie de l’observabilité, mais nous avons aussi construit notre première brique pratique. Nous avons vu que derrière ce concept se cache un mécanisme simple et élégant : des applications qui exposent leur état interne sur un simple endpoint HTTP.
Notre agent est fonctionnel, mais pour l’instant, personne ne l’écoute.
Dans le prochain article, nous déploierons un serveur Prometheus pour collecter ces métriques, puis nous les visualiserons dans Grafana pour voir notre application vivre en temps réel. La boucle sera bouclée.
D’ici là, n’hésitez pas à me faire part de vos retours !