Bonjour à tous, aujourd’hui on va parler un peu d’un terme qui est très important dans le petit monde du DevOps, et qui est surtout, au-delà même du DevOps, une façon de travailler qui est de plus en plus populaire : le GitOps.
![]()
Vous en entendez peut-être parler à droite à gauche, et vous vous demandez si c’est encore un buzzword à la mode ou un vrai game-changer. Accrochez-vous, parce qu’on va décortiquer ça ensemble, et vous allez voir que c’est plutôt la deuxième option !
Pour commencer : Pourquoi diable parler de Git ?
Avant de se jeter la tête la première dans GitOps, il faut qu’on ait tous les bases concernant un outil fondamental, la pierre angulaire de tout ça : Git.
Pour que vous compreniez bien ce qu’est Git, et pourquoi c’est si crucial, on va faire un petit cours d’histoire express. Déjà, il faut savoir qu’avant Git (et même encore parfois aujourd’hui, soyons honnêtes), les développeurs, et même nous les Ops quand on scriptait, on travaillait un peu… à l’arrache. Chacun sur sa machine, les modifs étaient individuelles, un vrai casse-tête à suivre, et n’essayez même pas d’imaginer fusionner les changements de plusieurs personnes sans sueurs froides. Les _v2_final_vraiment_final.sh, ça vous dit quelque chose :) ?
Bien sûr, il existait déjà des systèmes de gestion de versions, comme CVS ou SVN. C’était mieux que rien, mais ils avaient leurs limites, surtout pour gérer les conflits quand plusieurs personnes bossaient en même temps ou pour travailler de manière vraiment distribuée.
Et là, boom !

En 2005, Linus Torvalds, le papa de Linux, débarque avec Git. L’objectif ? Gérer le code source du noyau Linux, un monstre de complexité avec des milliers de contributeurs. Si vous voulez la petite histoire sympa sur comment Linus a eu cette idée (et franchement, c’est passionnant de voir son parcours pour ce projet), je vous conseille cet article : A Git Origin Story.
Pour la faire courte si vous êtes pressés : Linus utilisait un système commercial nommé BitKeeper. Commercial, donc un peu l’ennemi juré de l’esprit Open Source. Imaginez le tollé chez les puristes du noyau Linux de voir le “père” de l’Open Source utiliser un outil proprio pour le plus grand projet Open Source du monde ! Suite à des embrouilles sur les licences, Linus, fidèle à lui-même, a dit “Ok, je vais faire le mien, et il sera meilleur”. Et c’est comme ça que Git est né : rapide, performant, et surtout, distribué.
En résumé, Git, c’est un système de gestion de versions décentralisé. Chaque personne qui bosse sur le projet a une copie complète de tout l’historique sur sa machine. Ça permet de suivre chaque modification (qui, quoi, quand, pourquoi), de gérer facilement plusieurs versions d’un projet en parallèle avec les branches, de collaborer à plusieurs sans (trop) se marcher sur les pieds, et bien sûr, de revenir en arrière si on fait une bêtise (le fameux git revert salvateur !).
Aujourd’hui, Git, c’est la base. C’est un des premiers trucs qu’on apprend a l’ecole, ou même en autodidacte quand on touche au code.
“Ok, c’est bien beau ton histoire de Git pour les devs,” vous me dites, “mais nous, les sysadmins, les DevOps tendance Ops, les SRE, en quoi ça nous concerne directement ?” Patience, on y arrive ! C’est justement là que ça devient intéressant pour nous.
GitOps : Alors, c’est quoi le truc ?
Traditionnellement, et avouons-le, c’est encore souvent le cas, on gère nos serveurs “à l’ancienne”. On se connecte en SSH, on tape des commandes, on installe des paquets, on modifie des fichiers de conf, on déploie nos services… tout ça à la main. On a un serveur, on le bichonne, on le met à jour, et on espere que tout se passe bien et qu’on n’oublie rien.
Le problème ? Ce n’est pas fiable, c’est difficile à reproduire à l’identique, et surtout, ça ne scale absolument pas. Imaginez devoir faire la même config sur 10, 50, ou 100 serveurs… l’horreur, et la porte ouverte aux erreurs humaines. “Ça marche sur ma machine” version serveur, en somme.
Pour nous aider, on a vu arriver des outils d’automatisation géniaux comme Ansible, Puppet, Chef, ou encore Terraform pour l’Infrastructure as Code (IaC). Avec Ansible, on écrit des playbooks pour décrire les tâches à faire. Avec Terraform, on décrit l’état désiré de notre infrastructure. C’est déjà un pas de géant ! On code notre infra, c’est cool.
Et naturellement, comme c’est du code, on s’est dit : “Tiens, mais si on mettait nos playbooks Ansible et nos fichiers Terraform dans Git ?”. Et là, bingo ! On gagne une traçabilité impeccable, sachant qui a changé quoi et quand sur la définition de notre infra. On obtient aussi un historique complet, permettant de revenir à une version précédente si une mise à jour a tout cassé. Et enfin, la collaboration devient bien plus simple, permettant de travailler à plusieurs sur la même infra, avec des revues de code oui, des revues de code pour l’infra !
Ça, c’est déjà super. C’est faire de l’Infrastructure as Code versionnée avec Git. Mais GitOps, ça va encore un cran plus loin.
GitOps, c’est une méthodologie, un ensemble de pratiques, qui utilise Git comme unique source de vérité (Single Source of Truth) pour piloter de manière automatisée la configuration et le déploiement d’infrastructure et d’applications.
La phrase clé ici, c’est “piloter de manière automatisée”. Avec GitOps, l’état désiré de votre système est décrit de manière déclarative dans un ou plusieurs dépôts Git. Cet état dans Git devient la SEULE source de vérité ; si ce n’est pas dans Git, ça ne devrait pas exister en production, ou alors c’est une dérive ! Ensuite, des agents automatisés observent en permanence ce dépôt. Dès qu’un changement est fait dans la branche principale, ces agents s’en rendent compte et appliquent automatiquement ces changements à votre infrastructure pour qu’elle corresponde à ce qui est décrit dans Git. Enfin, ces agents s’assurent aussi que l’état réel ne dévie pas de l’état désiré. S’il y a une modif manuelle non désirée, l’agent peut la corriger ou vous alerter.
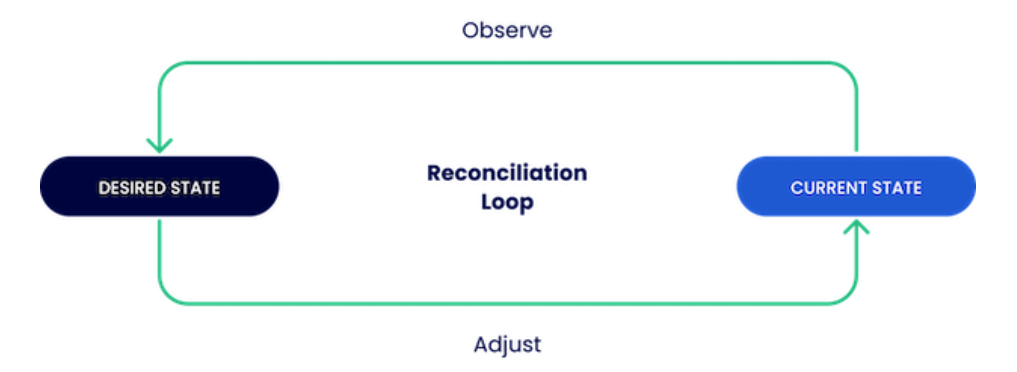
Imaginez un thermostat : vous réglez la température désirée (ce qui est dans Git). Le thermostat (l’agent GitOps) mesure la température actuelle de la pièce (l’état réel de votre infra) et allume ou éteint le chauffage (applique les changements) pour maintenir la température désirée. C’est exactement ça, mais pour toute votre stack technique !
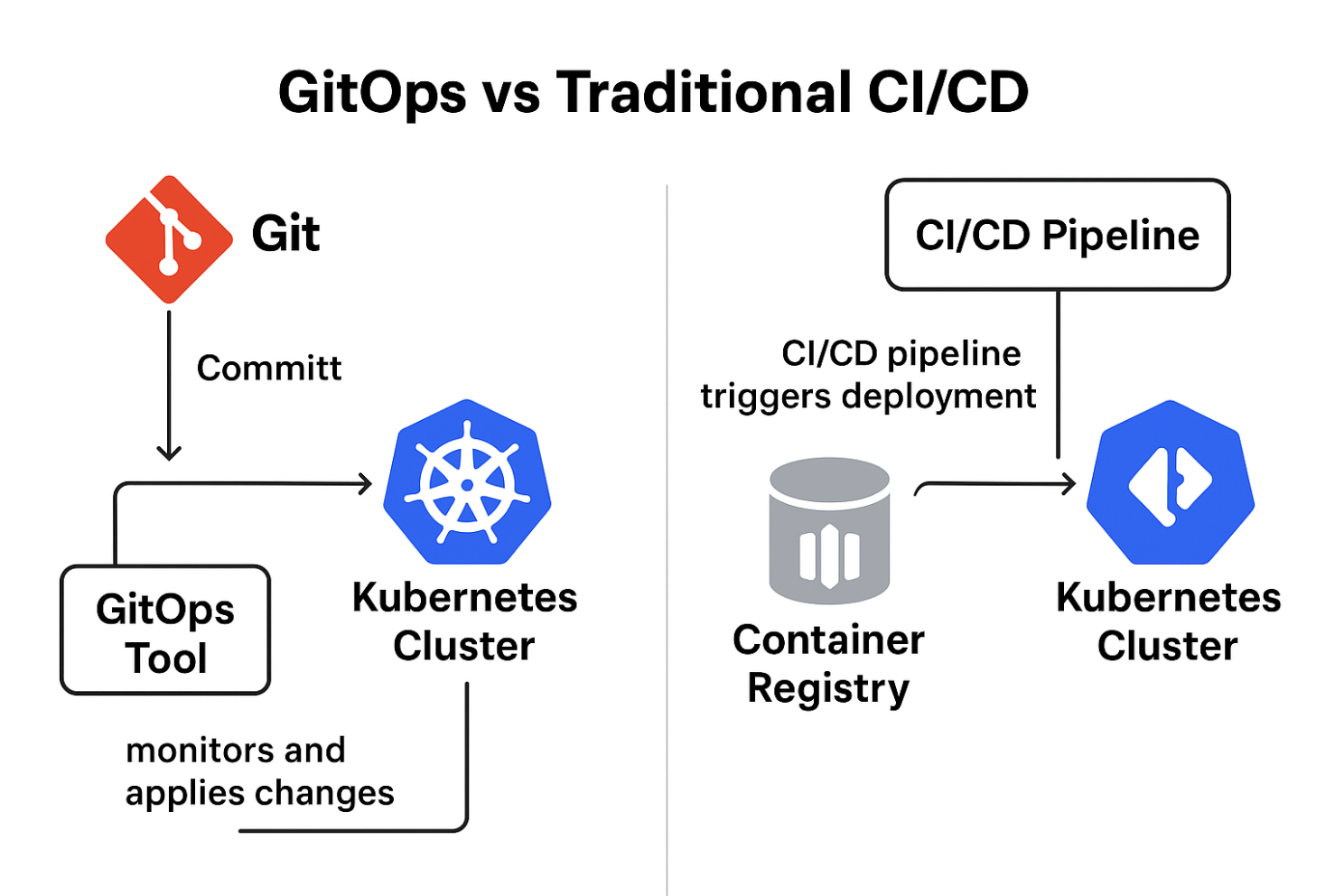
Donc, pour bien saisir la différence : faire de l’IaC avec Git, c’est écrire votre infra en code et la versionner. Pour appliquer, vous faites souvent un git pull puis un terraform apply ou ansible-playbook manuellement ou via un script de CI/CD simple. Avec GitOps, vous écrivez aussi votre infra en code et la versionnez, mais ensuite, des processus automatisés et continus prennent le relais pour que l’état réel de votre système converge en permanence vers ce qui est dans Git. Git devient véritablement le cockpit de votre infrastructure.
Les Piliers Fondamentaux du GitOps
Pour que ça soit vraiment du GitOps, et pas juste “on met nos trucs dans Git”, il y a quelques principes clés à respecter. On parle souvent de quatre piliers.
Premièrement, votre système doit être décrit de manière déclarative. On ne s’attarde pas sur le comment faire les choses (l’approche impérative : “installe ce paquet, puis configure ce fichier…”), mais on se concentre sur quel état on veut atteindre (l’approche déclarative : “je veux Nginx version X, avec tel fichier de conf…”). Kubernetes avec ses manifestes YAML est l’exemple parfait, mais Terraform suit aussi cette logique.
Deuxièmement, l’état désiré du système est versionné dans Git, qui est l’unique source de vérité. Tout ce qui définit votre environnement configurations d’applications, d’infrastructure, politiques réseau doit résider dans Git. Pour changer quelque chose, on modifie le code dans Git, jamais directement sur un serveur. Git devient la référence absolue.
Troisièmement, les changements approuvés dans Git sont appliqués automatiquement à l’environnement. Une fois qu’une modification est validée, typiquement via une Pull Request ou Merge Request, et fusionnée dans la branche principale (comme main ou master), un processus automatisé prend le relais pour déployer ces changements. Cela élimine les interventions manuelles risquées.
Enfin, quatrièmement, des agents ou workers/runners assurent la conformité et alertent en cas de dérive, c’est le principe de convergence. Des outils spécifiques, les fameux agents GitOps, tournent en continu pour comparer l’état réel de votre système avec l’état désiré dans Git. S’ils détectent une différence, ce qu’on appelle un “drift”, l’agent tente de réconcilier l’état réel avec l’état désiré, ou au minimum, il vous alerte. Cela garantit que votre système reste toujours conforme à ce que vous avez défini. Si vous cochez ces quatre cases, alors félicitations, vous êtes en plein dans une démarche GitOps !
Concrètement, ça ressemble à quoi un workflow GitOps ?
Ok, la théorie c’est bien, mais comment ça se passe en vrai ?
Imaginons que vous voulez mettre à jour la version d’une application qui tourne sur votre cluster Kubernetes.
Le processus commence par une demande de changement. Un développeur, ou un membre de l’équipe Ops, souhaite déployer la version v1.2.0 de l’application super-appli.
Ensuite, vient la modification déclarative. Cette personne ne se connecte pas directement au cluster Kubernetes. Au lieu de cela, elle se rend dans le dépôt Git qui contient les manifestes YAML de super-appli. Là, elle modifie le fichier deployment.yaml pour changer, par exemple, image: super-appli:v1.1.0 en image: super-appli:v1.2.0.
Après la modification, c’est l’étape du commit et du push. Elle enregistre son changement avec un message clair (git commit -m "feat: upgrade super-appli to v1.2.0") et le pousse sur une nouvelle branche (git push origin feature/upgrade-super-appli).
S’ensuit la création d’une Pull Request (ou Merge Request, selon la plateforme Git). Elle ouvre une PR de sa branche feature/upgrade-super-appli vers la branche principale, disons main.
C’est alors le moment de la revue et de la CI (Continuous Integration). D’autres membres de l’équipe examinent la PR pour discuter du changement et s’assurer de sa validité. Parallèlement, des tests automatisés peuvent se lancer, comme le linting des fichiers YAML, des vérifications de politiques de sécurité, voire un déploiement sur un environnement de test éphémère.
Si tout est validé, la PR est approuvée et fusionnée dans la branche main. C’est cet acte de fusion qui va effectivement déclencher le déploiement.
C’est là que l’Agent GitOps entre en jeu. Un outil comme Argo CD ou FluxCD, configuré pour surveiller la branche main de ce dépôt, détecte le nouveau commit. Il “voit” que le manifeste deployment.yaml a été modifié.
L’agent procède alors à la synchronisation. Il compare l’état désiré (le YAML dans Git) avec l’état actuel dans le cluster Kubernetes et constate la différence de version de l’image.
Vient ensuite l’application des changements.
L’agent applique la modification au cluster Kubernetes, qui va alors initier un déploiement progressif (rolling update) de super-appli vers la nouvelle version v1.2.0.
Enfin, le monitoring continu prend le relais. L’agent continue de surveiller. Si une modification manuelle non autorisée venait à altérer le déploiement dans Kubernetes, l’agent le détecterait et, selon sa configuration, pourrait soit corriger automatiquement pour revenir à l’état de Git, soit alerter l’équipe.
Et voilà ! Le changement est en production, de manière tracée, validée et automatisée, sans avoir eu à taper la moindre commande kubectl apply -f en croisant les doigts.
Quels sont les avantages concrets de cette approche ?
Vous commencez à le voir, adopter GitOps, ce n’est pas juste pour faire joli sur un PowerPoint. Ça apporte de vrais bénéfices tangibles au quotidien.
D’abord, on gagne énormément en fiabilité et en stabilité. Grâce à Git, l’état de votre système est entièrement défini et versionné, ce qui assure une reproductibilité parfaite : vous pouvez recréer un environnement à l’identique n’importe quand. Les rollbacks deviennent un jeu d’enfant ; si un déploiement tourne mal, un simple git revert sur le commit problématique permet à l’agent GitOps de ramener le système à son état stable précédent. C’est presque magique ! De plus, l’automatisation inhérente réduit drastiquement les erreurs humaines, qui sont si fréquentes lors d’interventions manuelles.
Ensuite, la productivité des équipes s’en trouve améliorée. Les déploiements deviennent plus rapides et peuvent être plus fréquents car le processus est automatisé et sécurisé, ce qui donne plus de confiance pour livrer. Cela peut aussi ouvrir la voie au self-service pour les développeurs, de manière contrôlée : ils peuvent proposer des changements sur leurs applications via des Pull Requests, en utilisant le même workflow que pour leur code applicatif, tandis que les Ops gardent le contrôle final via la validation des PRs et les politiques établies.
L’expérience des développeurs et des Ops s’améliore également. Les développeurs utilisent un outil qu’ils connaissent et maîtrisent parfaitement, Git. De leur côté, les Ops peuvent enfin se concentrer sur des tâches à plus forte valeur ajoutée, comme l’amélioration de la plateforme et l’optimisation des processus, plutôt que de passer leur temps sur des déploiements manuels répétitifs et stressants.
Sur le plan de la sécurité et de la conformité, les gains sont significatifs. L’historique Git fournit un audit trail complet et immuable, indiquant qui a changé quoi, quand, et (si les messages de commit sont bien rédigés) pourquoi. C’est une mine d’or pour les audits de sécurité ou de conformité. La validation des changements via les Pull Requests permet des revues par les pairs, y compris par les équipes de sécurité, avant toute mise en production. Et le mécanisme de convergence aide à la prévention de la dérive de configuration, l’agent s’assurant en permanence que l’état réel correspond à ce qui a été approuvé dans Git.
La gestion des environnements multiples (développement, staging, production) est aussi grandement simplifiée. On peut utiliser des stratégies basées sur des branches Git différentes, des répertoires distincts au sein d’un même dépôt, ou même des dépôts séparés, et laisser les agents GitOps s’occuper de la synchronisation spécifique à chaque environnement.
Enfin, GitOps offre une excellente scalabilité. Que vous ayez à gérer 10 ou 1000 services, un seul ou cinquante clusters Kubernetes, le principe fondamental reste le même. Git et les agents automatisés se chargent d’absorber une grande partie de la complexité inhérente à la taille. Bref, c’est une approche qui tend à rendre la gestion de nos systèmes modernes beaucoup plus sereine, prédictible et efficace.
Et les outils dans tout ça ? Quels sont les champions du GitOps ?
On a parlé d’ “agents GitOps”, mais qui sont-ils concrètement ? Sur le marché, et particulièrement dans l’écosystème Kubernetes, deux grands acteurs se distinguent nettement. Le premier est Argo CD, un projet hébergé par la CNCF (Cloud Native Computing Foundation). Il est très populaire et apprécié notamment pour son interface utilisateur graphique assez léchée qui permet de bien visualiser l’état des applications. Argo CD fonctionne sur un modèle de pull : il est installé directement dans votre cluster Kubernetes et va régulièrement “tirer” (pull) les configurations depuis les dépôts Git que vous lui indiquez. L’autre champion est FluxCD, également un projet de la CNCF. Il fut même le premier projet incubé par la fondation spécifiquement pour le GitOps ! FluxCD est reconnu pour sa puissance et sa flexibilité, et est souvent perçu comme ayant une approche peut-être un peu plus “native Kubernetes” dans sa philosophie. Lui aussi opère sur un modèle de pull, surveillant les dépôts Git pour appliquer les changements.
Ces outils sont conçus pour faire le gros du travail : surveiller vos dépôts Git et appliquer les configurations qu’il s’agisse de manifestes Kubernetes bruts, de charts Helm, ou de configurations Kustomize à vos clusters. Ce sont eux qui animent la boucle de réconciliation continue, garantissant que votre infrastructure reflète fidèlement ce qui est défini dans Git.
Il est important de souligner que, bien que GitOps soit très étroitement associé à Kubernetes, le concept n’est pas exclusivement lié à cet orchestrateur. On pourrait tout à fait imaginer et mettre en œuvre des systèmes GitOps pour gérer des parcs de machines virtuelles avec Terraform, par exemple, en ayant un orchestrateur personnalisé qui lirait l’état désiré depuis Git. Cependant, il est indéniable que Kubernetes constitue le terrain de jeu naturel et le plus mature pour l’application des pratiques GitOps aujourd’hui.
On ne va pas se lancer dans un tutoriel complet sur Argo CD ou FluxCD ici, cela mériterait un article dédié (et qui sait, peut-être une idée pour un prochain post ?). Mais il est essentiel de comprendre que ce sont ces outils qui transforment la théorie du GitOps en une réalité opérationnelle efficace.
Pour conclure (pour l’instant !)
Alors, le GitOps, simple effet de mode passager ou véritable révolution dans nos métiers ? J’espère sincèrement qu’après cette exploration, vous penchez plutôt pour la deuxième option. C’est une évolution logique et puissante de l’Infrastructure as Code, combinée aux meilleures pratiques DevOps. En plaçant Git au centre de toutes les opérations, comme unique et incontestable source de vérité, et en automatisant la synchronisation constante de l’état désiré avec l’état réel de nos systèmes, on gagne énormément en fiabilité, en vélocité et, il faut le dire, en sérénité.
C’est un véritable changement de paradigme : on ne “pousse” plus activement des configurations sur nos serveurs ou clusters. Au lieu de cela, on déclare un état cible dans Git, et on laisse le système, via ses agents automatisés, converger intelligemment vers cet état.
Bien sûr, la mise en place d’une stratégie GitOps demande un certain investissement initial. Il faut bien structurer ses dépôts Git, choisir et configurer l’agent GitOps adapté à ses besoins, et accompagner les équipes dans l’adoption de ces nouvelles pratiques. Mais les bénéfices à long terme sont considérables, surtout lorsqu’on opère dans des environnements techniques complexes et en constante évolution, comme c’est si souvent le cas aujourd’hui.
Dans un prochain article, on pourrait peut-être plonger les mains dans le cambouis avec un exemple pratique, en montant un workflow GitOps avec Argo CD ou FluxCD sur un petit cluster Kubernetes. Qu’est-ce que vous en dites ? Ça vous brancherait ?
En attendant, j’espère que cette introduction vous a été utile et vous a bien éclairé sur ce qu’est le GitOps. Si vous avez des questions, des remarques, ou si vous voulez partager votre propre expérience avec ces pratiques, n’hésitez surtout pas à le faire dans les commentaires ci-dessous !