Kubernetes pour les débutants - Partie 2
Re-bonjour à tous et bienvenus dans ce nouveau post à propos de Kubernetes. Je sais, j’ai failli à ma promesse, mais j’avais beaucoup de choses à faire récemment, donc vous m’excuserez.
Dans ce post, nous allons découvrir un peu plus de choses à propos de Kubernetes. Malgré le post 1 qui est là, j’ai l’impression que je suis parti un peu trop vite. Ici, dans ce post, nous allons prendre tout le temps nécessaire pour comprendre à quoi sert chaque élément qui compose un cluster Kubernetes. Peut-être que cela sera un peu rébarbatif ; je m’excuse d’avance pour cela. Pour maîtriser un outil tel que Kubernetes, il faut bien sûr passer par la théorie avant de passer à la pratique. Et cela est vrai pour n’importe quelle chose dans la vie.
Quelques rappels
Bon, je sais, le post 1 date un peu, donc vous avez besoin de quelques rappels. Je vais donner ci-dessous la liste des composants qui composent un cluster Kubernetes. Cette même liste va nous servir de guide pour expliquer chaque composant : à quoi il sert, comment il fonctionne, et comment l’implémenter :
- etcd
- API Server
- Kube-Scheduler
- Controller-Manager
- Kubelet
etcd
J’ai décidé de parler du etcd en premier, car c’est un des éléments les plus importants dans tout cluster Kubernetes. Il faut savoir que le etcd, c’est là où toutes les données du cluster sont stockées, c’est-à-dire l’état du cluster Kubernetes.
C’est quoi etcd ?
Selon la définition officielle, etcd, c’est : “etcd est un registre distribué, fortement cohérent, utilisé pour stocker des données de configuration et d’état dans des systèmes distribués.” Toute cette définition nous dit qu’etcd est en fait une base de données facile et très rapide.
etcd stocke toutes ses valeurs dans un format spécifique : key:value. Ce format est aussi utilisé dans les bases de données NoSQL, qui sont très utilisées dans des milieux où la rapidité est la pierre angulaire. Je ne suis pas là pour vous faire un cours à propos des bases de données, mais si vous le souhaitez, n’hésitez pas à me contacter ;)
Par exemple, etcd va stocker des valeurs de cette façon :
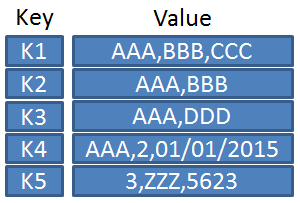
Donc, etcd, c’est une base de données. Par ailleurs, vous pouvez, si vous le voulez, installer etcd en standalone, c’est-à-dire sans avoir besoin de Kubernetes, et l’utiliser comme vous utiliseriez MongoDB ou une autre base de données NoSQL.
Je vais le répéter à nouveau : etcd, c’est le cœur de Kubernetes. Sans etcd, les autres éléments ne sauraient pas comment suivre les changements et répondre aux demandes de l’administrateur. Par exemple, si l’on veut ajouter un nouveau Pod, notre demande va être envoyée depuis l’ApiServer à l’etcd où la valeur du Pod va être ajoutée. Vu que le scheduler est là à regarder tout changement qui se passe dans l’ApiServer, il va se rendre compte qu’il y a un Pod qui n’a pas de nœud attribué, donc il va faire son boulot et dire à un nœud de créer ce Pod. Puis, l’ApiServer va mettre à jour l’etcd pour indiquer où se trouve le Pod créé.
Il existe des commandes pour maîtriser etcd, comme etcdctl. Cette commande permet de parler directement avec le service etcd et de récupérer toutes les infos qu’on veut. Voici quelques commandes qui peuvent être utilisées pour déboguer :
etcdctl snapshot save
etcdctl endpoint health
etcdctl get
etcdctl put
Elles sont intéressantes, mais à notre niveau, nous n’avons pas besoin de les connaître. Même si jamais on veut devenir des experts, il faudra les maîtriser et les utiliser fréquemment.
Api Server ou Kube API
Le Api Server, comme toute API, est la porte d’entrée d’un service. Dans notre cas, cela sera la seule porte d’entrée à notre cluster Kubernetes, c’est-à-dire l’accès aux autres éléments qui composent Kubernetes. Et même entre les services, seul l’Api Server peut directement écrire sur l’etcd. Tous les autres éléments sont obligés de passer par l’API.
Pour mieux vous faire comprendre, le Kube-API fait quatre choses principalement :
- Authentification
- Validation de la requête
- Récupération des données
- Mise à jour de l’etcd
Avant d’expliquer, je vais vous donner un scénario où l’on tape une commande pour créer un nouveau Pod :
kubectl run nginx --image=nginx
Ici, nous allons créer un Pod qui s’appelle nginx et qui a l’image du même nom.
Dans l’étape Authentification, l’Api-Server va vérifier si la personne qui envoie la requête a bien le droit d’accéder aux ressources. Une fois qu’il a validé que j’ai le droit, il va ensuite vérifier la syntaxe de la commande, si elle est correcte ou pas. Si elle est correcte et que j’ai bien le droit, il va récupérer ou écrire les données dans l’etcd. Ici, il va écrire dans l’etcd qu’il y a un nouveau Pod qui s’appelle nginx et dont l’image est aussi nginx.
Une fois qu’il a créé cette entrée, il va renvoyer à l’utilisateur que le Pod a bien été créé. Mais ça ne s’arrête pas ici ! Le scheduler, que nous détaillerons après, fait souvent des requêtes à l’Api Server pour savoir s’il y a de nouvelles choses à faire. Une fois qu’il découvre qu’il existe un nouveau Pod sans nœud attribué, il va envoyer au Kubelet d’un nœud de créer ce Pod. Une fois fait, l’ApiServer met à jour l’etcd et attribue le Pod au nœud que le scheduler a choisi.
Vous voyez, Kubernetes, ce n’est pas une chose simple, mais lorsqu’on comprend comment ça marche, on est quasiment “bouche bée” par rapport à la puissance de l’outil.
Kube-Scheduler
Pour comprendre à quoi sert le Kube-Scheduler, il faut d’abord comprendre quel problème il résout. Comme vous le savez (j’espère), Kubernetes est fait pour être en cluster. Et qui dit cluster dit nœuds, et qui dit nœuds dit qu’il y a une possibilité que ces nœuds ne soient pas pareils. Ils peuvent avoir des tailles différentes (RAM, CPU, stockage) et des usages différents (nœuds de pré-production, production). Comment fait-on donc pour placer les Pods dans le bon nœud ?
C’est là que le Kube-Scheduler entre en jeu. Le Kube-Scheduler est le composant essentiel qui va servir à placer les Pods dans les bons nœuds. Ne vous trompez pas, ce n’est pas le Kube-Scheduler qui place les Pods dans les nœuds ; lui, il est là pour décider seulement. C’est le Kubelet, qui est dans chaque nœud, qui va placer le Pod.
Prenons un cas pratique : imaginons un Pod qui a besoin d’au moins 6 Go de RAM pour fonctionner. Nous avons 4 nœuds : 2 nœuds avec 5 Go de RAM, un avec 12 Go de RAM et le dernier avec 15 Go de RAM. Le scheduler suit une procédure pour décider dans quel nœud il doit placer ce Pod.
Premièrement, il va Filtrer les nœuds qui respectent ou non les critères du Pod, c’est-à-dire un minimum de 6 Go. Donc, les deux premiers nœuds sont en dehors de la liste. Il nous reste maintenant les deux derniers nœuds à 12 Go et 15 Go de RAM.
Le Kube-Scheduler utilise une méthode de ranking où il va classer les nœuds selon quelques critères. Par défaut, il va regarder combien de ressources il restera si jamais le Pod est placé dans ce nœud. Si on le place sur le premier à 12 Go de RAM, il restera 6 Go de RAM, et si on le place sur le deuxième à 15 Go de RAM, il restera 9 Go de RAM. Donc, le deuxième gagne car il a une meilleure note.
Certes, c’est une façon un peu ancienne de décider, mais rien ne nous empêche de créer notre propre Kube-Scheduler, que nous pourrons personnaliser et faire fonctionner à notre façon. Mais bien sûr, par défaut, il existe d’autres critères qu’on verra dans d’autres posts qui aident le Kube-Scheduler à décider où mettre le Pod.
Controller-Manager
Les controllers sont un des éléments les plus importants dans tout cluster Kubernetes. Un controller est un service qui surveille constamment un autre composant du cluster. Le controller est là pour amener l’état du cluster vers l’état désiré par l’administrateur. Il existe plusieurs controllers. Les plus importants sont :
- Node Controller
- Deployment Controller
- ReplicaSet Controller
- Service Controller
Je rappelle qu’il existe bien d’autres controllers. Pour vous faire réaliser l’importance d’un controller, parlons du Node Controller.
Le Node Controller est là pour surveiller l’état des nœuds et il est là pour prendre les actions nécessaires pour garder l’application en vie. Par défaut, un nœud envoie un signal de vie ou “heartbeat” toutes les 5 secondes. Si vous avez bien suivi, vous allez deviner que le Node Controller utilise le Kube-API pour avoir ces informations. Si jamais un nœud arrête d’envoyer un heartbeat au Node Controller, celui-ci va attendre 40 secondes, et si jamais il ne reçoit toujours pas de heartbeat, il va le marquer comme unreachable.
Une fois que le nœud est marqué comme unreachable, le Node Controller va attendre 5 minutes pour que le nœud revienne à la vie. S’il ne le fait pas, il va enlever tous les Pods qui étaient attribués au nœud (au moins ceux qui font partie d’un ReplicaSet, vous allez savoir ce que c’est dans le prochain article ;) ), et il va les mettre dans d’autres nœuds pour permettre à l’application de continuer.
Comme vous venez de le découvrir, les controllers sont le cerveau d’un cluster Kubernetes. C’est ce qui permet aux administrateurs de dormir le soir (je rigole, les sysadmins ne dorment pas). Chaque service ou composant que je vais expliquer dans d’autres parties ou d’autres posts, un controller est là pour le surveiller et monitorer son état.
Cette image explique très bien le processus d’un controller :
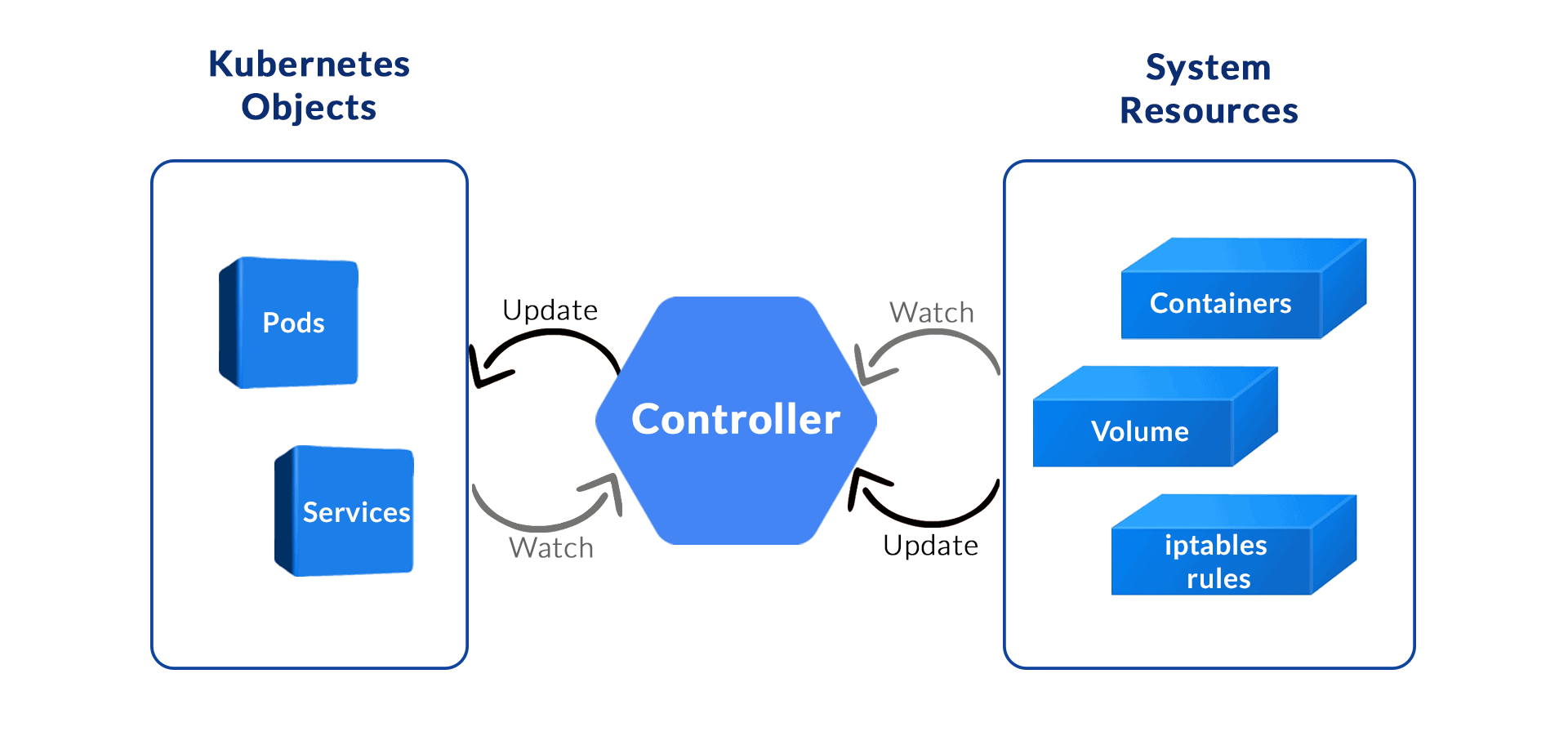
Kubelet
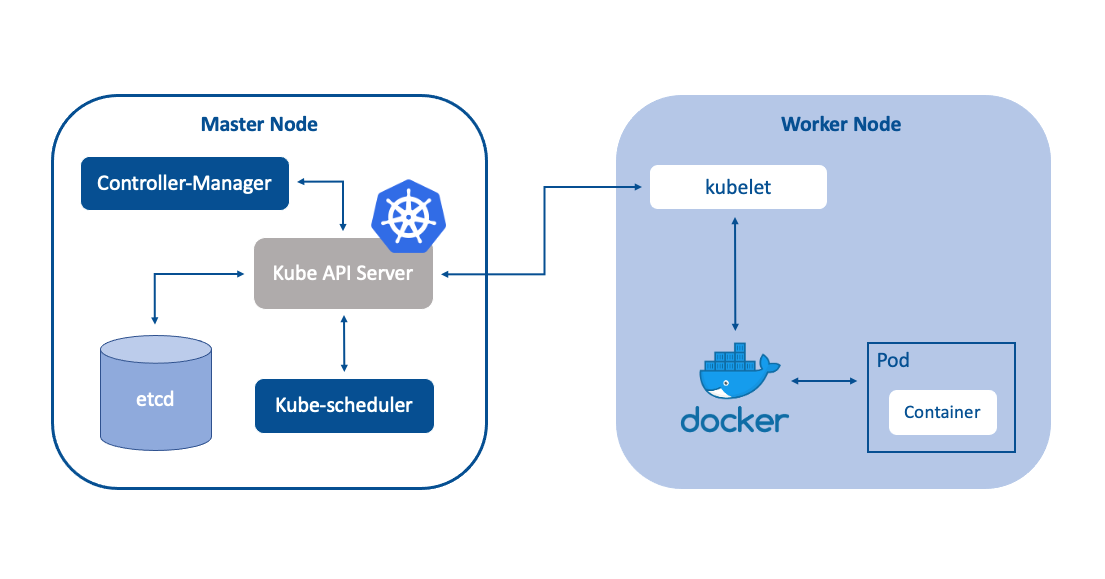
Finalement, le dernier, mais pas le moins important, le Kubelet. Le Kubelet est le service de Kubernetes qui permet à un nœud de rejoindre un cluster.
C’est le service qui va faire tout le travail brut, c’est-à-dire que c’est lui qui va dire à son container-runtime, du genre Docker ou Podman, de pull l’image du Pod et de créer le container. Également, le Kubelet est là pour surveiller l’état des Pods qui sont à l’intérieur de lui.
Ci-dessous, une image qui représente cela :
Conclusion
Kubernetes est un outil puissant qui révolutionne la gestion des conteneurs et des applications en environnement distribué. Dans cette deuxième partie, nous avons exploré en détail les composants essentiels de Kubernetes, tels qu’etcd, l’API Server, le Kube-Scheduler, le Controller-Manager, et le Kubelet. Chacun de ces éléments joue un rôle crucial dans le fonctionnement d’un cluster, assurant une orchestration efficace et fiable des ressources.
En comprenant ces composants et leur interaction, vous serez mieux préparé à déployer et à gérer vos applications dans Kubernetes. N’oubliez pas que la maîtrise de cet outil nécessite du temps et de la pratique, mais avec patience et persévérance, vous pourrez tirer pleinement parti de sa puissance. Dans les prochaines parties, nous approfondirons d’autres fonctionnalités et concepts avancés, vous permettant de renforcer vos compétences et d’optimiser votre utilisation de Kubernetes. Restez à l’écoute !