
Depuis quelques temps, on les voit partout ce genre d’images. Sur Reddit, LinkedIn… Même dans les journaux et sur les chaînes TV !
Depuis qu’OpenAI a lancé la dernière mise à jour de son IA DALL-E (ou même Google avec son modèle Gemini), on voit déferler des images d’une qualité incroyable. Mais surtout des mèmes ou des concepts fous devenir réalité visuelle ! On ne s’en rend peut-être pas encore pleinement compte, mais c’est une avancée majeure dans le monde de l’IA. Le fait que le grand public ait accès aussi facilement à ce genre de technologie est une véritable révolution.
Créer des logos, des illustrations pour des articles, des visuels publicitaires, retoucher des photos… Tout cela en quelques secondes, juste avec du texte. C’est un gain de temps potentiellement incroyable pour les créatifs, mais aussi une nouvelle forme d’expression accessible à tous pour les sites web ou les réseaux sociaux.
Mais il y a un “mais”. Un problème de taille. Où vont vos images ? Qui les stocke ? Qui peut les voir ? Qui les analyse ? Ces IA génératives si populaires sont massivement hébergées sur des serveurs aux États-Unis. Et qui dit entreprise américaine, dit potentiellement CLOUD Act. Cette loi permet aux autorités américaines, sous certaines conditions, d’accéder aux données stockées par ces entreprises, où qu’elles soient dans le monde. Donc, oui, vos prompts (qui peuvent contenir des idées confidentielles) et vos images peuvent être consultés.
En tant qu’Européen, Africain, ou simplement citoyen soucieux de sa vie privée, la question se pose : est-ce que je souhaite que mes créations, mes idées, soient potentiellement accessibles à des services étrangers ? Où est la souveraineté numérique dans tout ça ?
On ne peut pas simplement dépendre des services d’entreprises américaines pour des technologies aussi stratégiques. Il nous faut des alternatives. L’exemple de la dépendance excessive de certains états européens envers Microsoft pour leurs infrastructures critiques est là pour nous le rappeler.
Heureusement, pour la génération d’images aussi, des modèles open source existent. Mieux encore, ils peuvent tourner en local, directement sur votre machine ! (Certes, il faut souvent une carte graphique décente – cette autonomie demande un certain investissement matériel – mais c’est possible). On pense notamment à Stable Diffusion, le plus connu et la base de tout un écosystème, mais aussi à d’autres projets comme Flux.
Dans cet article, nous allons justement déployer un de ces modèles sur mon pc personnel modeste mais capable :
- AMD Ryzen 5 5600H
- 32Go de RAM
- Nvidia RTX 3060
L’objectif est de montrer concrètement qu’il est possible de générer des images sans passer par des services cloud étrangers, en gardant le contrôle total sur ses données. Et surtout, de comprendre un peu comment ça marche.
ATTENTION
Le but ici n’est pas de faire une comparaison de qualité brute. Les modèles fermés comme DALL-E 3 ou Midjourney bénéficient de ressources de calcul quasi illimitées et d’investissements colossaux qui leur donnent souvent un avantage en termes de facilité d’utilisation et de performance “brute”. Une comparaison directe est difficile. Cependant, nous allons voir que la qualité obtenue en local est déjà impressionnante, largement suffisante pour de très nombreux usages, et offre surtout une flexibilité et un contrôle inégalés. L’essentiel est de montrer que l’alternative locale existe, fonctionne, et protège votre vie privée.
Prérequis
Bien entendu on va faire tourner des modèles IA en local, donc il faut avoir un minimum de puissance de calcul. Pour ce tutoriel, on va utiliser un GPU Nvidia, mais il est possible de faire tourner ces modèles sur un CPU, même si c’est beaucoup plus lent.
Je vous recommande vivement de prendre une GPU Nvidia. Au moins 4Go de VRAM sont nécessaires pour commencer, mais 6Go ou idéalement 8Go (ou plus) sont fortement recommandés pour plus de confort, pour utiliser des modèles plus récents (comme SDXL) et avoir des générations plus rapides ou en plus haute résolution. Les cartes graphiques Nvidia sont souvent plus performantes que les cartes AMD pour ce genre de tâches grâce à l’écosystème CUDA pour lequel beaucoup de modèles IA sont optimisés.
Installation de EasyDiffusion
Ici dans cet article, on va utiliser EasyDiffusion, une interface (un “wrapper”) autour de Stable Diffusion qui permet de générer des images facilement, sans se prendre la tête avec des lignes de commande.
Pour l’installation sous Windows c’est vraiment très très simple. Il suffit de se rendre sur le site officiel de EasyDiffusion et de télécharger le fichier .exe.
Ou vous pouvez cliquer ici pour télécharger directement le fichier d’installation Windows depuis leur page GitHub Releases.
Le fichier n’est pas signé par une autorité reconnue par Windows. Il est donc possible que Windows Defender ou votre navigateur affiche un avertissement (SmartScreen, etc.). C’est un projet open source maintenu par la communauté ; si vous l’avez téléchargé depuis le lien officiel GitHub, vous pouvez l’exécuter sans crainte en choisissant “Informations complémentaires” puis “Exécuter quand même”.
Une fois le fichier téléchargé, lancez-le et suivez les instructions (choisir le dossier d’installation, etc.). Détendez-vous, car la première décompression et installation va prendre un peu de temps.
Pendant l’installation, il va préparer tout ce qu’il faut pour faire marcher l’interface web et télécharger un modèle IA de base (Stable Diffusion v1.5) pour qu’on puisse tester directement.
Une fois l’installateur terminé, lancez EasyDiffusion depuis le menu Démarrer ou le raccourci créé.
Et non, ce n’est toujours pas fini ! Au premier lancement, une fenêtre de terminal va s’ouvrir et EasyDiffusion va télécharger les dernières librairies Python nécessaires (PyTorch, transformers, etc.) et configurer l’environnement. Là aussi, patience, ça peut prendre plusieurs minutes selon votre connexion internet.
Quand tout est prêt, vous verrez apparaître dans le terminal un message indiquant que le serveur est lancé et accessible.
Utilisation de EasyDiffusion
Une fois que le terminal indique que tout est prêt, vous pouvez ouvrir votre navigateur web et vous rendre à l’adresse indiquée, généralement : http://localhost:9000/
Et voilà l’interface :
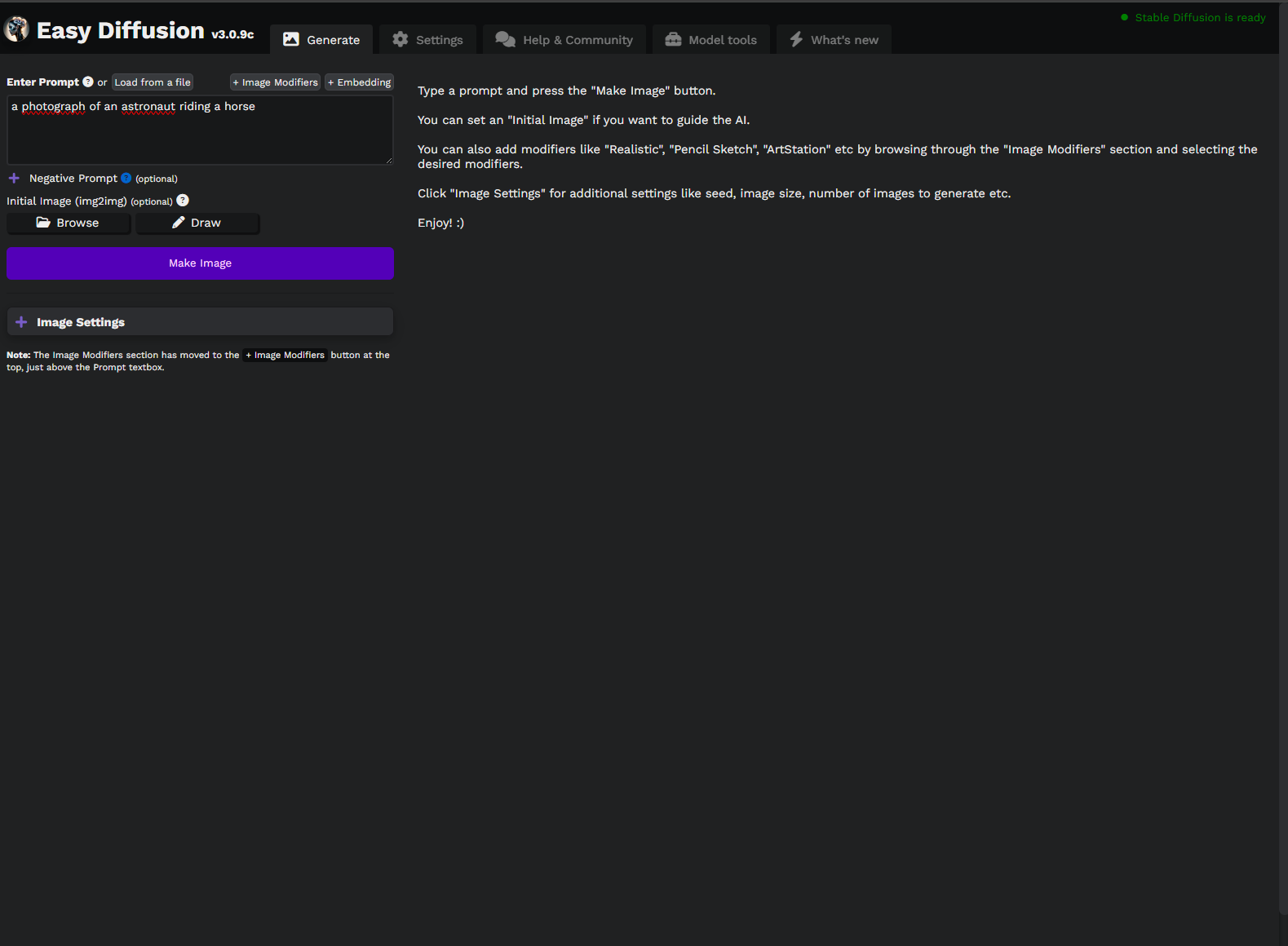
Ici vous avez pas mal d’options. On y retrouve bien sûr la zone pour écrire le prompt (la description de l’image qu’on veut), mais aussi plein d’autres réglages comme le Negative Prompt (ce qu’on ne veut pas voir), le choix du modèle (Model), le Sampler, le nombre d’étapes d’inférence (Steps), la taille de l’image (Image Size), etc. Pour l’instant, restons simple.
Cliquez sur “Image Settings” pour voir les détails. Vous devriez voir le modèle qui a été installé par défaut :
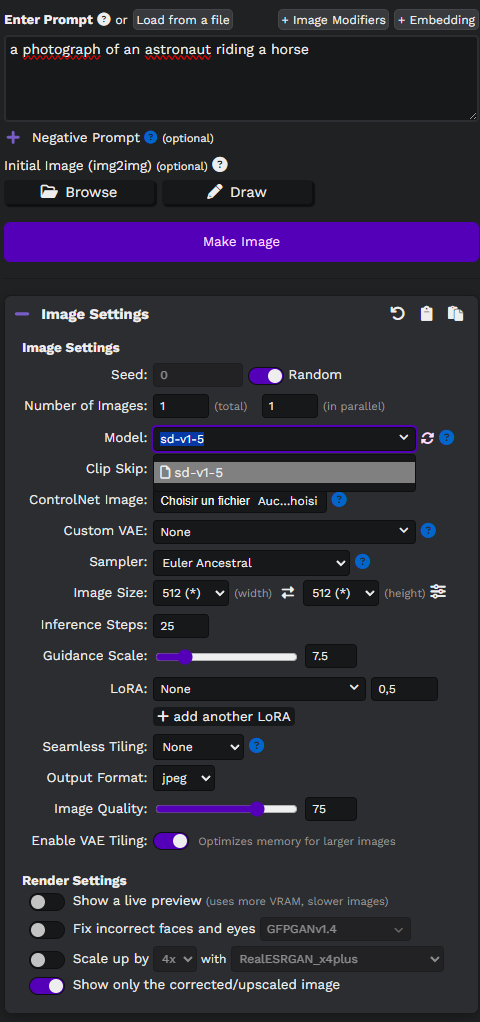
On voit que l’installeur nous a téléchargé le modèle nommé sd-v1.5. C’est la version 1.5 de Stable Diffusion, sortie en 2022. Dans le monde de l’IA, c’est presque la préhistoire ! Mais ça reste un modèle solide pour générer des images simples et comprendre le principe.
Essayons ! Mettons un prompt simple comme “Create an aesthetic photo of a french croissant” (Créez une photo esthétique d’un croissant français) et cliquons sur “Make Image”. Voici le processus :
Et voilà ! En quelques secondes (le temps dépendra beaucoup de votre carte graphique), on a une image de croissant. C’est pas mal pour un début, non ?
Mais bon, comme je disais, sd-v1.5 c’est bien pour commencer, mais ça date un peu. Pour avoir des résultats plus modernes, plus photoréalistes, ou dans des styles particuliers (anime, peinture à l’huile, etc.), il faut utiliser des modèles plus récents ou spécialisés, entraînés par la communauté.
Où les trouver ? Il existe des plateformes qui hébergent ces modèles IA partagés. L’une des plus connues, notamment dans le monde de la recherche et de l’open source, est Hugging Face. Vous pouvez y chercher des modèles “text-to-image” (texte vers image). Vous y trouverez les modèles de base officiels Stable Diffusion (comme SD 1.5, SD 2.1, SDXL) et beaucoup d’autres créés par des chercheurs ou la communauté. Faites bien attention aux licences d’utilisation de chaque modèle si vous comptez utiliser les images générées pour autre chose qu’un usage personnel.
Généralement, on cherche des fichiers avec l’extension .safetensors. Ce format est aujourd’hui préféré à l’ancien format .ckpt car il est considéré comme plus sûr (il ne contient pas de code arbitraire potentiellement exécutable, juste les “poids” du modèle).
Une fois que vous avez trouvé et téléchargé un fichier .safetensors qui vous intéresse (par exemple, un modèle spécialisé dans le photoréalisme, ou un style artistique précis), il suffit de le placer dans le bon dossier pour qu’EasyDiffusion le reconnaisse automatiquement :
C:\EasyDiffusion\models\stable-diffusion
(Adaptez le chemin C:\EasyDiffusion si vous l’avez installé ailleurs).
Pour cet exemple, j’ai téléchargé et ajouté un modèle axé photoréalisme nommé Epic Realism. Une fois le fichier copié dans le dossier, il faut parfois rafraîchir la liste des modèles dans EasyDiffusion (il y a un petit bouton de rafraîchissement à côté du menu déroulant du modèle) ou redémarrer EasyDiffusion.
Et voilà le processus : on sélectionne le nouveau modèle dans la liste déroulante “Model”, on garde le même prompt, et on génère à nouveau :
On voit que le résultat est différent, souvent plus détaillé ou stylisé selon le modèle choisi. En moins de 30 secondes pour changer de modèle, on peut explorer des rendus variés.
Après bien entendu, il y a beaucoup d’options pour affiner le résultat. On peut jouer avec le sampler (la méthode de “dessin” de l’image), le nombre d’itérations (Steps - plus il y en a, plus l’image est détaillée, mais plus c’est long), la CFG Scale (à quel point l’IA doit suivre le prompt), et même utiliser des LoRAs (des petits modèles additionnels pour affiner un style, un personnage ou un concept). Bref, on peut faire plein de choses pour personnaliser ses créations.
Alors, Prêt à Reprendre le Contrôle ?
Voilà la preuve par l’exemple ! Générer des images IA sur son propre PC, c’est faisable et plus simple qu’on ne le pense avec des outils comme EasyDiffusion.
Oui, ça demande une machine qui tient un minimum la route et un peu de temps pour s’y mettre, là où les services cloud brillent par leur facilité immédiate. Mais le gain est ailleurs, et il est de taille : le contrôle total et la confidentialité de vos données. Fini de se demander où partent vos créations ou qui peut y accéder à cause du CLOUD Act.
Alors, même si DALL-E ou Midjourney sont impressionnants, l’alternative locale existe, elle est puissante et elle vous appartient vraiment.
Pourquoi ne pas sauter le pas et reprendre le contrôle de vos pixels ? Lancez-vous !