Aujourd’hui, je vais vous donner un retour d’expérience complet sur un projet qui me tient à cœur : SentinelBox (le nom est mauvais oui, mais j’ai du en trouver un…). Ici, je vais créer de A à Z un modèle d’IA pour détecter les anomalies réseau sur un cluster Proxmox.
Ce sera un article long et technique, mais je vais quand meme essayer de faire quelque chose de ludique. On va passer par la mise en place de l’infrastructure Proxmox jusqu’à la création du modèle d’IA, et même sa mise en production avec Prometheus et Grafana. Je vous promets, ça va être une aventure où j’apprendrai autant que vous, enfin je l’espère en tout cas. Bon, assez de blabla, c’est parti !
Disclaimer : Je ne suis pas un expert en IA, vraiment pas. Je suis juste un simple étudiant avec des idées, qui aime bien les partager. Si vous voyez des erreurs ou des points à améliorer, n’hésitez pas à me le dire, je suis là pour apprendre.
Introduction
Ces dernières années, avec l’émergence de technologies comme ChatGPT, Gemini et d’autres, j’ai commencé à m’intéresser aux IA, surtout au côté LLM (Large Language Model – ce qui permet de générer du texte en fonction des inputs utilisateurs) et au NLP (Natural Language Processing). J’ai donc suivi quelques cours sur YouTube, lu des articles sur Medium et ailleurs et meme des theses sur arxive. Et franchement, c’est super intéressant.
Même si je ne pense pas faire de l’IA mon métier, je me suis senti obligé d’en apprendre davantage. Dans cet article, je vais vous montrer comment j’ai réussi à créer un modèle d’IA pour détecter des anomalies réseau sur un cluster Proxmox. Ce modèle est assez modeste, entraîné sur un dataset que j’ai trouvé sur internet (je vais aussi vous expliquer comment créer votre propre dataset si besoin).
Je préfère vous prévenir : les concepts peuvent paraître complexes, mais l’application que je vais vous présenter dans cet article tient en à peine 40 lignes de Python.
Alors, pas de panique, on va y aller doucement !
L’idee du projet
L’objectif de ce projet est de déployer un système intelligent de détection d’anomalies réseau sur un cluster Proxmox, en combinant intelligence artificielle et quelque outils du monde des SysAdmin.
L’idée centrale est de capturer le trafic réseau du cluster via des outils comme tcpdump et FluentD, puis de l’analyser en temps réel à l’aide d’un modèle d’IA entraîné pour distinguer les comportements normaux des activités suspectes (scans non autorisés, tentatives de DDoS, etc.). Le modèle, développé avec TensorFlow et des techniques de machine learning simplifiées, sera hébergé dans un conteneur Docker pour faciliter son déploiement et sa scalabilité .
Le déploiement sur Docker facilite une future migration vers Kubernetes – idéal pour surveiller des clusters géants !.
Les prédictions du modèle seront ensuite transmises à Prometheus pour l’agrégation des métriques, puis visualisées sur un dashboard Grafana. Enfin, un système d’alerte sera mis en place pour notifier les administrateurs en cas de détection d’anomalies (bonus).
Voila une idee que j’ai eu, je ne sais pas si c’est faisable, mais je vais essayer de le faire. Ce post sera soit le recit d’une reussite, soit le recit d’un parcours d’apprentissage, dans les deux cas j’apprendrais moi, et vous aussi.
Notre infrastructure
Pour ce projet, j’ai decide de prendre un cluster Proxmox que j’ai sous la main, c’est un total de deux serveurs Lenovo ThinkCenter. Avec chaqu’un 8go de RAM, donc rien de spectaculaire, mais c’est suffisant pour ce que je veux faire.
Voila un petit diagramme de notre infra:
Donc une infra plutot classique avec un cluster Proxmox, un routeur et une connexion internet pour chaque VM. Si vous voulez plus de details sur comment est-ce que j’ai mis en place ce cluster, n’hesitez pas a me le dire, je ferais un autre article pour expliquer tout ça (parce que le router c’est une VM dans mon pc perso, donc j’en ai des choses a dire dessus).
Installation et configuration de la VM
Pour ce projet, j’ai decide de creer une seule VM ubuntu 24.04 sur l’ensemble de mon cluster. Cette VM sera notre machine de travail, c’est ici que nous allons deployer notre modele IA, et les differents outils comme Prometheus et Grafana.
ça sera une VM ubuntu 24.04 avec 2go de RAM et 40go de disque et 2 coeurs CPU, rien de special.
Voila la config materielle de ma VM, vue depuis Proxmox :
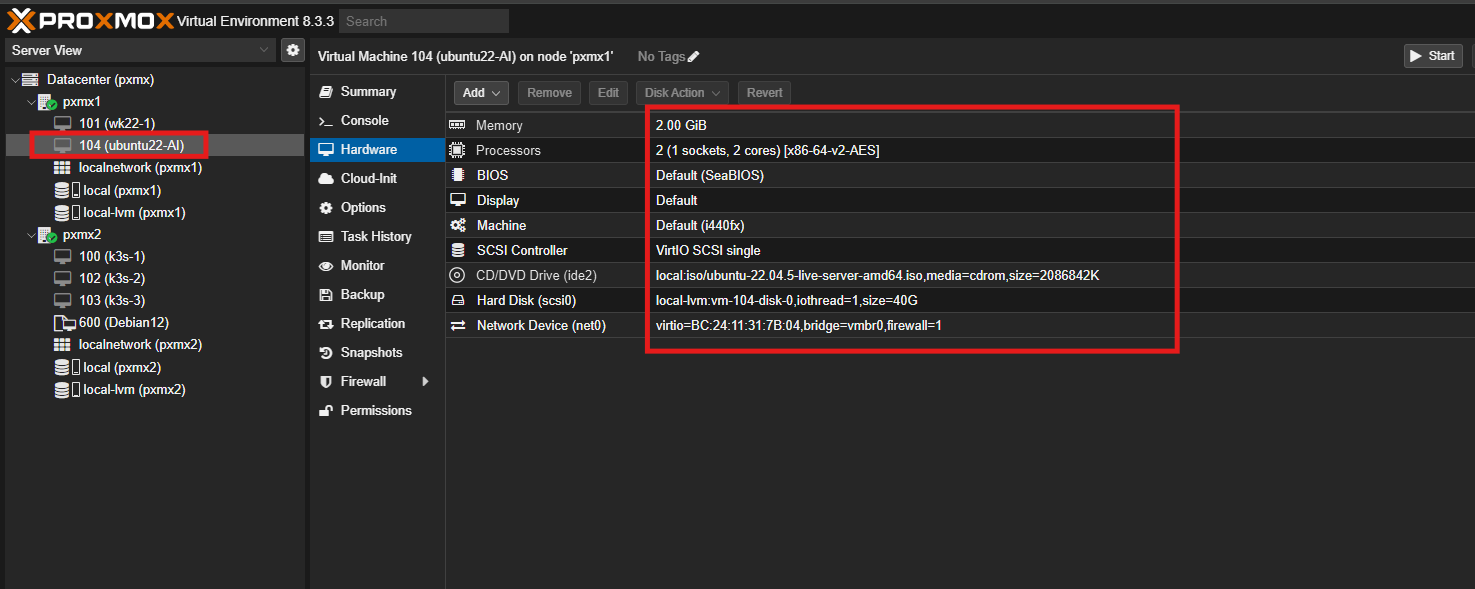
Avant de commencer a capturer des paquets pour notre modele IA, on va d’abord configurer la VM.
On va installer Docker dessus, c’est ce qui va nous permettre d’heberger notre modele IA ainsi que grafana et prometheus. Pour cela on va suivre la documentation officielle de Docker, et on va l’installer en utilisant le script officiel :
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
Et juste avec cela, vous avez docker et meme docker compose de installer sur votre VM !
Capturer les paquets réseau
Maintenant passons a une etape un peu plus drole, nous devons maintenant capturer les paquets réseau qui circulent, pour essayer de definir ce qui est normal pour que apres notre modele IA puisse detecter ce qui n’est pas normal.
Pour cela on va utiliser l’outil incontestable tcpdump, c’est un outil qui permet de capturer les paquets réseau sur une interface donnee. On va donc capturer les paquets réseau sur l’interface reseau du Proxmox, c’est a dire vmbr0. Puis cette capture on va la sauvegarder dans un fichier .pcap pour pouvoir l’analyser et utiliser plus tard.
La syntaxe de tcpdump n’est pas complique, on va juste lui dire de capturer les paquets sur l’interface vmbr0 et de les sauvegarder dans un fichier .pcap :
sudo tcpdump -i vmbr0 -s 0 -w capture.pcap
Lorsque on lance cette commande vous verrez quelque chose qui ressemble a cela :
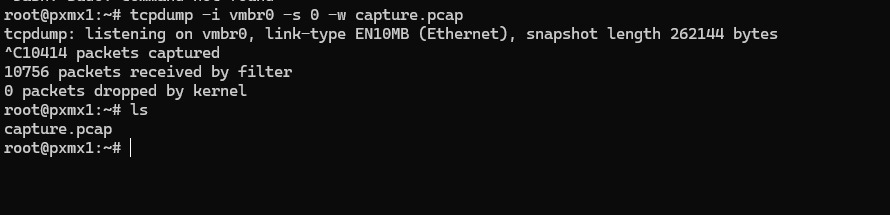
Comme vous voyez dans l’image j’ai laisse tourner la commande pendant quelques minutes et j’ai reussi a recuperer 10414 paquets.
C’est pas mal, mais c’est pas assez pour entrainer un modele IA. Pour entrainer une modele IA il faut des milliers pour ne pas dire des millions de paquets. Donc pour cela on va utiliser un dataset que j’ai trouve sur internet, c’est un dataset qui contient des métriques agrégées (durée, nombre de paquets, etc.) pour chaque connexion, idéales pour entraîner notre modèle sans surcharge, ou il y a eu un scan de ports, c’est tout ce qu’il nous faut. Pour pouvoir differencier les paquets normaux des paquets anormaux.
Entraîner le modèle IA
Bon, là, on arrive à la partie vraiment sympa, le cœur du projet : l’entraînement de notre intelligence artificielle !
Pour faire ça, on va sortir l’artillerie lourde, enfin façon de parler, on va plutôt utiliser des outils : TensorFlow, et plus précisément un autre sous-librairie dedans qui s’appelle TensorFlow Decision Forests. Ces noms peuvent faire un peu peur au début, mais en fait, c’est pas si compliqué que ça. En gros, ce sont des librairies, qui vont nous aider à construire et à apprendre à notre modèle IA à faire son boulot de détection réseau.
Pourquoi on choisit TensorFlow et Decision Forests ?
Alors, TensorFlow, c’est un peu le “must-have” dans le monde de l’IA en ce moment. C’est un outil super puissant que Google a mis à disposition de tout le monde gratuitement. C’est un peu comme avoir une super boîte à outils remplie d’outils géniaux pour construire toutes sortes de modèles IA, du plus simple au plus fou. Pour nous, c’est parfait, parce que c’est solide, ça marche bien, et il y a plein de documentation si jamais on est bloqué. En plus, TensorFlow, ça va nous servir non seulement pour entraîner notre IA, mais aussi pour la faire tourner après, quand elle sera en mode “surveillance” dans notre docker.
Et dans TensorFlow, on va se concentrer sur un truc qui s’appelle Decision Forests, ou en français “Forêts d’Arbres Décisionnels”. C’est un peu technique comme nom, mais l’idée est assez simple à comprendre. Imagine que tu veux prendre une décision, par exemple, “est-ce que ce trafic réseau est normal ou bizarre ?”. Tu peux te poser une série de questions : “Est-ce que ça vient de cette adresse IP ? Est-ce que ça utilise ce type de protocole ? Est-ce que la taille des paquets est inhabituelle ?”. Un arbre de décision, c’est un peu comme un arbre de questions comme ça.
Et une forêt d’arbres, c’est plein d’arbres qui donnent leur avis, et à la fin, on prend la décision majoritaire.
Pourquoi on utilise ça, les forêts d’arbres ? Il y a plusieurs raisons :
- C’est assez rapide : Pour entraîner ce type de modèle, ça va plutôt vite, même avec pas mal de données. C’est pratique, on n’a pas besoin d’attendre des heures.
- C’est pas hyper compliqué : Comparé à d’autres trucs d’IA super complexes, les forêts d’arbres, c’est plus simple à comprendre et à mettre en place. Pour commencer, c’est top, on se prend pas trop la tête.
- Ça marche bien avec nos données : Les infos qu’on va récupérer du trafic réseau, ça se présente souvent en tableaux, avec des colonnes (l’adresse IP, le port, le protocole…). Et les arbres de décision, ils sont super à l’aise avec ce genre de données en tableau.
- C’est fort pour détecter les trucs bizarres : Les forêts d’arbres, ça apprend bien à voir ce qui est “normal” dans le trafic réseau. Après, si y’a un truc qui sort de l’ordinaire, un truc qui ne ressemble pas à ce qu’il a appris comme “normal”, hop, il peut nous le signaler comme une anomalie potentielle.
Du coup, pour notre AI, on va utiliser un modèle qu’on appelle Random Forest, c’est un type de forêt d’arbres très populaire et efficace. C’est un peu comme si on avait plein de petits détectives (les arbres) qui regardent chacun le trafic réseau sous un angle différent, et à la fin, ils mettent leurs conclusions en commun pour dire “attention, là, y’a un truc louche !” ou “tranquille, tout est normal”. C’est plus solide qu’un seul détective, forcément.
Nos données d’entraînement, le fameux CIC-IDS2017
Pour que notre IA apprenne à détecter les anomalies, il faut lui montrer des exemples, lui donner des “cours”. Pour ça, on va utiliser un dataset, un jeu de données, qui s’appelle CIC-IDS2017. C’est un dataset un peu connu dans le monde de la sécurité réseau. En gros, c’est un enregistrement de trafic réseau, où il y a du trafic normal, mais aussi plein d’attaques différentes (des attaques pour bloquer un serveur, des tentatives d’intrusion, des scans de ports…). C’est pas le dataset parfait, il commence à dater un peu, mais pour nous, c’est parfait pour démarrer et pour tester notre idée. Ça va nous donner une base pour apprendre à notre modèle ce qui est normal et ce qui ne l’est pas.
Pour telecharger ce dataset vous l’aurez sous format .parquet dans le lient suivant : https://www.kaggle.com/datasets/dhoogla/cicids2017/data
Et après ça, on a notre dataset nickel pour commencer à entraîner notre IA !
Le code Python pour entraîner notre IA
Le code Python que nous allons utiliser ressemble a cela :
import pandas as pd
import tensorflow as tf
import tensorflow_decision_forests as tfdf
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 1. Charger les données
df = pd.read_parquet('Portscan-Friday-no-metadata.parquet')
# 2. Prétraitement
df['Label'] = df['Label'].apply(lambda x: 0 if x == 'Benign' else 1)
features = df.drop('Label', axis=1)
labels = df['Label']
# 3. Split des données
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# 4. Conversion pour TensorFlow
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(
X_train.join(y_train),
label='Label',
task=tfdf.keras.Task.CLASSIFICATION
)
# 5. Entraînement du modèle
model = tfdf.keras.RandomForestModel(
num_trees=100,
max_depth=12,
task=tfdf.keras.Task.CLASSIFICATION,
verbose=0
)
model.fit(train_ds)
# 6. Sauvegarde pour TensorFlow Serving
model.save('saved_model', save_format='tf')
# 7. Évaluation
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(
X_test.join(y_test),
label='Label',
task=tfdf.keras.Task.CLASSIFICATION
)
y_pred = model.predict(test_ds)
y_pred = [1 if p > 0.5 else 0 for p in y_pred]
print("\nRapport de classification:")
print(classification_report(y_test, y_pred))
Une petite explication du code s’impose :
- Tout d’abord il charge les données : Il prend notre dataset CIC-IDS2017 (le fichier Parquet) il faudra bien entendu l’importer dans google collab.
- Il prépare un peu les données : Il fait un peu de ménage, il transforme une colonne qui dit si c’est normal ou une attaque en chiffres (0 et 1, plus simple pour l’IA).
- Il sépare les données : Il coupe notre dataset en deux tas. Un tas pour l’entraînement, pour que l’IA apprenne, et un autre tas pour tester après, pour voir si l’IA a bien compris la leçon.
- Il entraîne le modèle Random Forest : Là, c’est le moment où l’IA apprend vraiment ! Avec
tensorflow_decision_forests, on lui dit “entraîne-toi sur ces données, apprends à reconnaître le trafic normal et anormal”. On lui donne quelques réglages, comme le nombre de “détectives” (d’arbres) et leur profondeur de réflexion (la profondeur des arbres). - Il teste le modèle : Une fois entraîné, on lui donne le tas de données qu’il n’a jamais vu (l’autre moitie du dataset). On regarde s’il arrive à bien détecter les anomalies, si ses prédictions sont justes.
- Il sauvegarde le modèle : Si l’examen est réussi, on enregistre notre modèle IA entraîné. On le met dans une boîte (un format spécial,
saved_model) pour pouvoir le réutiliser après dans notre container Docker.
Ce code nous allons le lancer dans google collab (Un genre de jupyter notebook ou google nous donne gratuitement une grande puissance de calcul, c’est beaucoup utilise par les gens qui font du Data science et meme de l’IA). Ce qui va nous permettre de profiter de la puissance de google collab pour entrainer notre modele.
Avant de lancer le code bien entendu il faut installer les dependances, pour cela il va suffir de mettre un bloc de code au dessus du code python qui ressemble a cela :
!pip install tensorflow_decision_forests pyarrow scikit-learn
Et voila, il va suffir maintenant d’executer le code de toutes les cellules, dans le menu Execution. Et vous devriez voir quelque chome comme cela :
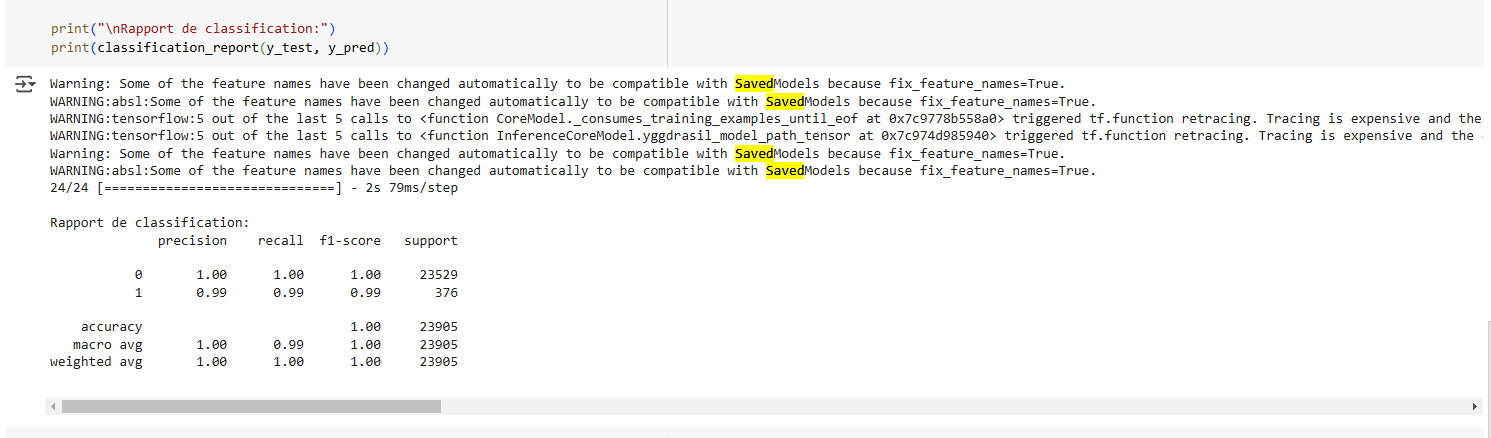
Ici on peut voir que notre modele a une Précision Globale (accuracy) de 99.97%, ce qui est excellent !! Donc Seulement 7 erreurs sur 23 905 tests. Ce qui est juste incroyble.
Voilà ! Après tout ça, on a notre modèle IA entraîné et emballé, prêt à être lâché sur notre réseau Proxmox pour faire son boulot !.
Maintenant, la prochaine grosse étape, c’est de sortir notre modèle IA de Google Colab et de le mettre au travail dans notre VM Proxmox. Parce que pour l’instant, il est un peu au chaud dans le cloud de Google, mais nous, on veut qu’il surveille notre réseau, notre Proxmox.
Déploiement du modèle dans notre VM
Alors, la première chose qu’on va faire, c’est de se connecter en SSH à notre VM Ubuntu qu’on a préparée. Une fois qu’on est connecté en ligne de commande dans notre VM, on va commencer par créer un petit coin où ranger tous les fichiers de notre projet SentinelBox. On va faire ça avec une commande toute simple :
mkdir sentinelbox && cd sentinelbox
En gros, avec cette ligne, on crée un dossier qu’on a appelé sentinelbox.
Maintenant, on va utiliser Docker pour heberger tous les outils qu’on va utiliser. Si vous n’avez jamais entendu de docker de votre vie, j’ai une serie ou je presente Docker :
En résumé si jamais vous ne voulez pas aller voir mon post, Docker, c’est un peu comme des boîtes, des “containers”, dans lesquelles on va pouvoir mettre notre modèle IA, Prometheus, Grafana, et tout ce dont on a besoin pour SentinelBox. L’avantage, c’est que chaque boîte est isolée, bien rangée, et surtout, super facile à installer et à lancer. Plus besoin de se prendre la tête avec des installations compliquées, Docker fait presque tout le boulot pour nous.
Pour piloter tout ça avec Docker, on va utiliser un outil qui s’appelle Docker Compose. Docker Compose, c’est un peu le chef d’orchestre de nos containers Docker. Avec un simple fichier de configuration, qu’on va créer juste après, Docker Compose va se charger de lancer tous nos containers dans le bon ordre, de les connecter entre eux, et de faire en sorte que tout fonctionne ensemble comme sur des roulettes.
Alors, la première chose à faire, c’est de créer ce fameux fichier de configuration pour Docker Compose. On va l’appeler compose.yaml. Dans le dossier sentinelbox qu’on vient de créer :
nano compose.yaml
Et là, dans ce fichier vide, on va coller notre docker compose. Accroche-vous, je vous montre le code, et après je vous explique ce que ça fait :
services:
tensorflow-serving:
image: tensorflow/serving:latest
ports:
- "8501:8501" # Port pour les requêtes gRPC et REST
volumes:
- ./models:/models # Monte un volume local pour les modèles
environment:
MODEL_NAME: sentinel_model # Nom du modèle (important pour les requêtes)
prometheus:
image: prom/prometheus:latest
ports:
- "9090:9090" # Port d'accès à l'interface Prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
depends_on:
- tensorflow-serving
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000" # Port d'accès à l'interface Grafana
volumes:
- grafana-data:/var/lib/grafana
depends_on:
- prometheus
volumes:
grafana-data: # Volume pour persister les données Grafana
models: # Volume pour les modèles
Bon, ça peut paraître un peu barbare comme ça, mais en fait, c’est assez logique. On va décortiquer ça ensemble :
services:: Là, on dit à Docker Compose qu’on va lancer plusieurs “services”, plusieurs boîtes Docker, qui vont travailler ensemble. Dans notre cas, on en a trois principaux :tensorflow-serving:: C’est ici qu’on va mettre notre modèle IA !tensorflow-servingc’est un outil de Google fait exprès pour faire tourner des modèles TensorFlow comme le nôtre.image: tensorflow/serving:latest-cpu: Ça dit à Docker de prendre une image Docker déjà toute prête qui contient TensorFlow Serving.ports: - "8501:8501": Ça, c’est pour dire que notre container TensorFlow Serving va être accessible depuis l’extérieur de la VM sur le port 8501. On utilisera ce port pour envoyer des données à notre modèle IA pour qu’il les analyse.volumes: - ./models:/models: Là, c’est super important ! On dit à Docker de connecter un dossier de notre VM,./models(le dossiermodelsqui est dans le même répertoire quedocker-compose.yml), à un dossier à l’intérieur du container,/models. En gros, tout ce qu’on mettra dans le dossiermodelsde notre VM sera accessible par TensorFlow Serving dans son container. C’est là qu’on va mettre notre modèle IA !environment: MODEL_NAME: sentinel_model: Ça, c’est une petite variable d’environnement qu’on donne à TensorFlow Serving. On lui dit que le nom de notre modèle, c’estsentinel_model. On aura besoin de ce nom plus tard.
prometheus:: Prometheus, c’est un outil qu’on va utiliser pour surveiller le fonctionnement de SentinelBox. Il va collecter des informations (des “métriques”) sur TensorFlow Serving, pour qu’on puisse voir si tout va bien, s’il y a des erreurs, etc.image: prom/prometheus:latest: Comme pour TensorFlow Serving, on prend une image Docker Prometheus déjà prête.ports: - "9090:9090": Prometheus sera accessible sur le port 9090. On utilisera un navigateur web pour voir son interface.volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml: Là aussi, on connecte un fichier de notre VM,./prometheus.yml(qu’on va créer après), à un fichier de configuration de Prometheus dans le container,/etc/prometheus/prometheus.yml. C’est dansprometheus.ymlqu’on va dire à Prometheus quoi surveiller.depends_on: - tensorflow-serving: Ça, c’est pour dire à Docker Compose que Prometheus doit démarrer après TensorFlow Serving. Parce que Prometheus a besoin de TensorFlow Serving pour faire son boulot de surveillance.
grafana:: Grafana, c’est l’outil qui va nous permettre de visualiser les informations collectées par Prometheus. On va créer des jolis graphiques, des tableaux de bord, pour voir en un coup d’œil ce qui se passe dans SentinelBox.image: grafana/grafana:latest: Image Docker Grafana toute prête.ports: - "3000:3000": Grafana accessible sur le port 3000. Interface web aussi.volumes: - grafana-data:/var/lib/grafana: Ici, au lieu de connecter un fichier précis, on utilise un “volume nommé” Docker,grafana-data. Docker va créer un espace de stockage spécial pour Grafana, et il conservera les données de Grafana même si on arrête et redémarre le container. C’est pratique pour garder nos tableaux de bord configurés.depends_on: - prometheus: Grafana démarre après Prometheus, logique, il a besoin de Prometheus pour afficher des données.
volumes:: En bas, on définit les “volumes nommés” qu’on utilise, ici justegrafana-data. Et on redéfinit aussimodels, même si c’est pas obligatoire ici, c’est plus propre.
Bon, je sais, ça fait beaucoup d’infos d’un coup. Mais l’idée principale, c’est que ce fichier docker-compose.yml, c’est la recette complète pour lancer notre SentinelBox avec Docker. On va avoir trois containers qui tournent ensemble : TensorFlow Serving (avec notre IA), Prometheus (pour la surveillance), et Grafana (pour la visualisation).
Maintenant on va pull toutes les images de notre compose, pour cela il faut simplement taper la commande :
sudo docker compose pull
Vous aurez quelque chose quiva ressembler a cela :
Déploiement du modèle dans notre VM (suite et fin !)
Mettons maintenant notre modèle IA au bon endroit pour que TensorFlow Serving puisse le trouver. Comme nous l’avons vu dans notre fichier compose.yaml, nous avons défini un volume qui lie un dossier local de notre VM, ./models, au dossier /models à l’intérieur du container tensorflow-serving.
Il faut donc créer ce dossier models à la racine de votre dossier sentinelbox, si ce n’est pas déjà fait. Ensuite, à l’intérieur de ce dossier models, nous devons créer un sous-dossier nommé sentinel_model. Cette structure, models/sentinel_model/1/, est la convention attendue par TensorFlow Serving pour organiser les versions de modèles.
Si vous avez bien suivi, nous avons entraîné notre modèle IA dans Google Colab et nous l’avons sauvegardé dans un dossier nommé saved_model. Il faut maintenant copier le contenu du dossier saved_model (tout le contenu, pas le dossier lui-même) dans le dossier models/sentinel_model/1/ de votre VM.
Vous pouvez utiliser scp, ou votre outil de transfert de fichiers préféré pour réaliser cette opération. Assurez-vous de bien copier tous les fichiers et dossiers qui se trouvent à l’intérieur de saved_model dans models/1/.
Une fois cette copie effectuée, vérifiez que la structure de vos dossiers ressemble bien à ceci :
.
├── compose.yaml
├── models
│ └── sentinel_model
│ └── 1
│ ├── assets
│ │ ├── e6004b5eb87f4508data_spec.pb
│ │ ├── e6004b5eb87f4508done
│ │ ├── e6004b5eb87f4508header.pb
│ │ ├── e6004b5eb87f4508nodes-00000-of-00001
│ │ └── e6004b5eb87f4508random_forest_header.pb
│ ├── fingerprint.pb
│ ├── keras_metadata.pb
│ ├── saved_model.pb
│ └── variables
│ ├── variables.data-00000-of-00001
│ └── variables.index
└── prometheus.yml
(La présence du dossier assets peut varier en fonction de votre modèle et de la manière dont il a été sauvegardé). L’important est de voir saved_model.pb et le dossier variables dans models/1/.
Bien entendu il ne faut oublier le prometheus.yml sinon le container prometheus va refuser de demarrer le contenu de ce fichier sera le suivant :
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'tensorflow-serving'
static_configs:
- targets: ['tensorflow-serving:8501'] # Nom du service Docker et port TensorFlow Serving
Rien de bien complique donc je me reserve le fait de le commenter :) …
Lancement de SentinelBox avec Docker Compose
Dans le même répertoire sentinelbox où se trouvent votre fichier compose.yaml et votre dossier models, il suffit de lancer la commande magique :
sudo docker compose up -d
docker compose up, c’est la commande qui dit à Docker Compose de démarrer tous les services définis dans compose.yaml. L’option -d permet de lancer les containers en mode “detached”, c’est-à-dire en arrière-plan. Votre terminal sera donc libéré, et les containers continueront de tourner en tâche de fond.
Docker Compose va maintenant se charger de :
- Créer les volumes Docker (comme
grafana-data). - Lancer le container
tensorflow-servingen utilisant l’imagetensorflow/serving:latestet en montant le volume./models:/models. - Lancer le container
prometheusen utilisant l’imageprom/prometheus:latest, en montant le volume./prometheus.yml:/etc/prometheus/prometheus.ymlet en s’assurant qu’il démarre aprèstensorflow-serving. - Lancer le container
grafanaen utilisant l’imagegrafana/grafana:latest, en utilisant le volumegrafana-dataet en s’assurant qu’il démarre aprèsprometheus.
Vous devriez voir un affichage dans votre terminal qui indique la création des containers et leur démarrage. Pour vérifier que tout s’est bien passé, vous pouvez utiliser la commande :
sudo docker compose ps
Et vous devriez voir quelque chose qui ressemble a cela :
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
sentinelbox-grafana-1 grafana/grafana:latest "/run.sh" grafana 22 minutes ago Up 21 minutes 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp
sentinelbox-prometheus-1 prom/prometheus:latest "/bin/prometheus --c…" prometheus 22 minutes ago Up 21 minutes 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp
sentinelbox-tensorflow-serving-1 tensorflow/serving:latest "/usr/bin/tf_serving…" tensorflow-serving 22 minutes ago Up 21 minutes 8500/tcp, 0.0.0.0:8501->8501/tcp, :::8501->8501/tcp
Attention ! Pour le container tensorflow-serving j’ai du changer le type de CPU par host sur proxmox, sinon le docker refusait de demarrer !
Cette commande vous donnera l’état des containers lancés par Docker Compose. Vous devriez voir tensorflow-serving, prometheus et grafana avec le statut “Up” ou “running”. Si jamais un container a un problème, son statut vous l’indiquera, et vous pourrez examiner les logs avec la commande docker compose logs <nom_du_service> (par exemple, docker compose logs tensorflow-serving).
Test du modele
Maintenant, il nous reste encore une chose à faire avant d’aller sur Grafana : tester le modèle.
Pour cela, nous avons une magnifique API qui va nous permettre de discuter avec notre modèle d’IA et ainsi obtenir une réponse pour savoir s’il détecte ce type de trafic comme malicieux ou non.
Pour le tester, nous allons utiliser une commande curl. Cette commande va envoyer un paquet créé par nous-mêmes, uniquement à des fins de test.
Voici à quoi ressemble la commande curl :
curl -X POST \
-H "Content-Type: application/json" \
-d '{
"instances": [
{
"ACK_Flag_Count": 0,
"Active_Max": 0,
"Active_Mean": 0.0,
"Active_Min": 0,
"Active_Std": 0.0,
"Avg_Bwd_Segment_Size": 0.0,
"Avg_Fwd_Segment_Size": 0.0,
"Avg_Packet_Size": 0.0,
"Bwd_Avg_Bulk_Rate": 0,
"Bwd_Avg_Bytes/Bulk": 0,
"Bwd_Avg_Packets/Bulk": 0,
"Bwd_Header_Length": 0,
"Bwd_IAT_Max": 0,
"Bwd_IAT_Mean": 0.0,
"Bwd_IAT_Min": 0,
"Bwd_IAT_Std": 0.0,
"Bwd_IAT_Total": 0,
"Bwd_PSH_Flags": 0,
"Bwd_Packet_Length_Max": 0,
"Bwd_Packet_Length_Mean": 0.0,
"Bwd_Packet_Length_Min": 0,
"Bwd_Packet_Length_Std": 0.0,
"Bwd_Packets/s": 0.0,
"Bwd_Packets_Length_Total": 0,
"Bwd_URG_Flags": 0,
"CWE_Flag_Count": 0,
"Down/Up_Ratio": 0,
"ECE_Flag_Count": 0,
"FIN_Flag_Count": 0,
"Flow_Bytes/s": 0.0,
"Flow_Duration": 1200000,
"Flow_IAT_Max": 0,
"Flow_IAT_Mean": 0.0,
"Flow_IAT_Min": 0,
"Flow_IAT_Std": 0.0,
"Flow_Packets/s": 0.0,
"Fwd_Act_Data_Packets": 0,
"Fwd_Avg_Bulk_Rate": 0,
"Fwd_Avg_Bytes/Bulk": 0,
"Fwd_Avg_Packets/Bulk": 0,
"Fwd_Header_Length": 0,
"Fwd_IAT_Max": 0,
"Fwd_IAT_Mean": 0.0,
"Fwd_IAT_Min": 0,
"Fwd_IAT_Std": 0.0,
"Fwd_IAT_Total": 0,
"Fwd_PSH_Flags": 0,
"Fwd_Packet_Length_Max": 0,
"Fwd_Packet_Length_Mean": 0.0,
"Fwd_Packet_Length_Min": 0,
"Fwd_Packet_Length_Std": 0.0,
"Fwd_Packets/s": 0.0,
"Fwd_Packets_Length_Total": 0,
"Fwd_Seg_Size_Min": 0,
"Fwd_URG_Flags": 0,
"Idle_Max": 0,
"Idle_Mean": 0.0,
"Idle_Min": 0,
"Idle_Std": 0.0,
"Init_Bwd_Win_Bytes": 0,
"Init_Fwd_Win_Bytes": 0,
"PSH_Flag_Count": 0,
"Packet_Length_Max": 0,
"Packet_Length_Mean": 0.0,
"Packet_Length_Min": 0,
"Packet_Length_Std": 0.0,
"Packet_Length_Variance": 0.0,
"Protocol": 0,
"RST_Flag_Count": 0,
"SYN_Flag_Count": 0,
"Subflow_Bwd_Bytes": 0,
"Subflow_Bwd_Packets": 0,
"Subflow_Fwd_Bytes": 0,
"Subflow_Fwd_Packets": 0,
"Total_Backward_Packets": 0,
"Total_Fwd_Packets": 0,
"URG_Flag_Count": 0
}
]
}' \
http://localhost:8501/v1/models/sentinel_model:predict
Oui je sais elle est tres longue, mais pour faire marcher les predictions du modele on doit mettre toutes les valeurs aves lesquelles il a ete entraine, peut etre il y a un moyen de ne mettre que certains champs, mais j’ai pas su comment faire…
En tout cas dans l’etat ça marche, donc voila a quoi ressemble le retour que vous devriez avoir :
ça marche !!!

Avec ce résultat, on peut déduire que le paquet envoyé a 0,08 (ou 8 %) de chances d’être malicieux. C’est logique, car j’ai utilisé des valeurs aléatoires, et la majorité sont des zéros.
Donc, jusque-là, notre modèle fonctionne et est bien en vie !
Et maintenant ?
Félicitations ! Si tout s’est déroulé comme prévu, vous avez maintenant SentinelBox qui tourne sur votre VM Proxmox, grâce à Docker Compose. Nous avons déployé notre modèle IA, Prometheus pour la surveillance, et Grafana pour la visualisation.
Dans le prochain article, nous allons enfin pouvoir accéder aux interfaces web de Prometheus et Grafana pour vérifier que tout fonctionne correctement. Nous allons également commencer à configurer Prometheus pour qu’il surveille TensorFlow Serving, et Grafana pour visualiser les métriques. Et bien sûr, l’étape cruciale, nous allons envoyer du trafic réseau à notre SentinelBox pour voir si notre IA de détection d’anomalies fait bien son travail (en dehors des donnees de test)
Si vous avez des remarques ou des suggestions, n’hesitez pas a m’en faire part !